Profiling Web Archives
Sawood Alam and Michael L. Nelson
Computer Science Department, Old Dominion University
Norfolk, Virginia - 23529
Herbert Van de Sompel
Los Alamos National Laboratory, Los Alamos, NM
David S. H. Rosenthal
Stanford University Libraries, Stanford, CA
Memento Aggregator
- Aggregates ~20 archives and counting
- Only a few archives return good results for any query
- Time, network, and resource wastage
- Query routing can be helpful
Long Tail Matters
- 400B+ web pages at IA do not cover everything
- Top three archives after IA produce full TimeMap 52% of the time
- Targeted crawls
- Special focus archives
- Restricted resources
- Private archives
The Portuguese Web Archive and Memento unveil the first homepage of the Smithsonian Institution from May 1995... http://t.co/5I3eKehFJL
— PortugueseWebArchive (@PT_WebArchive) January 5, 2015Dennis Ritchie's Homepage has been deleted: http://t.co/H3gPyxEyHx - and the site has a robots.txt that blocks it from the Wayback.
— Jason Scott (@textfiles) April 22, 2015Memento Workflow
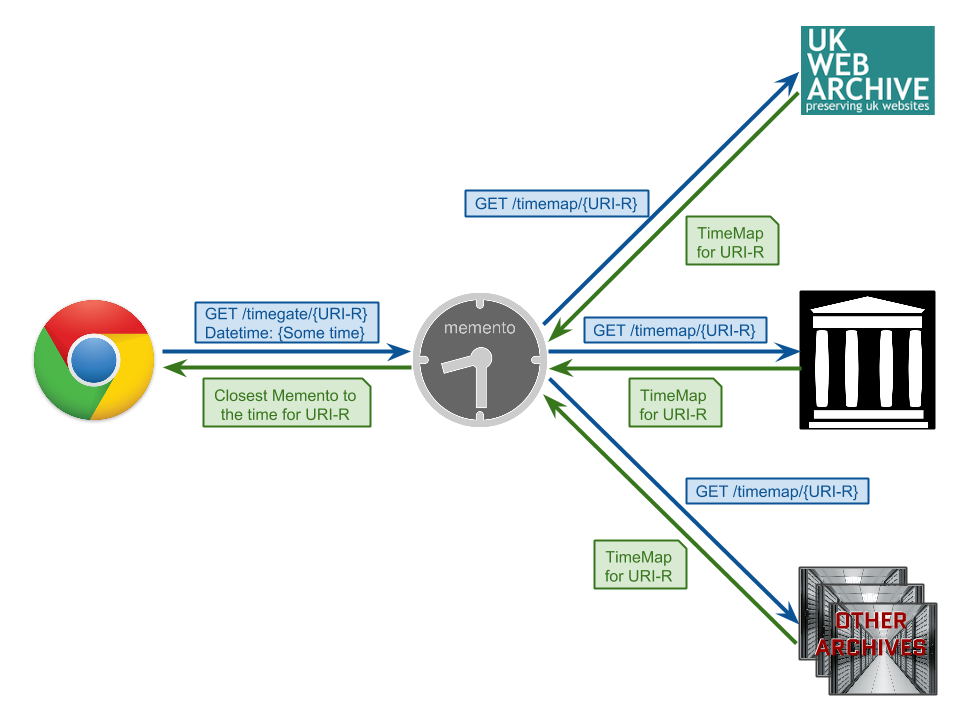
Memento Workflow with Profile
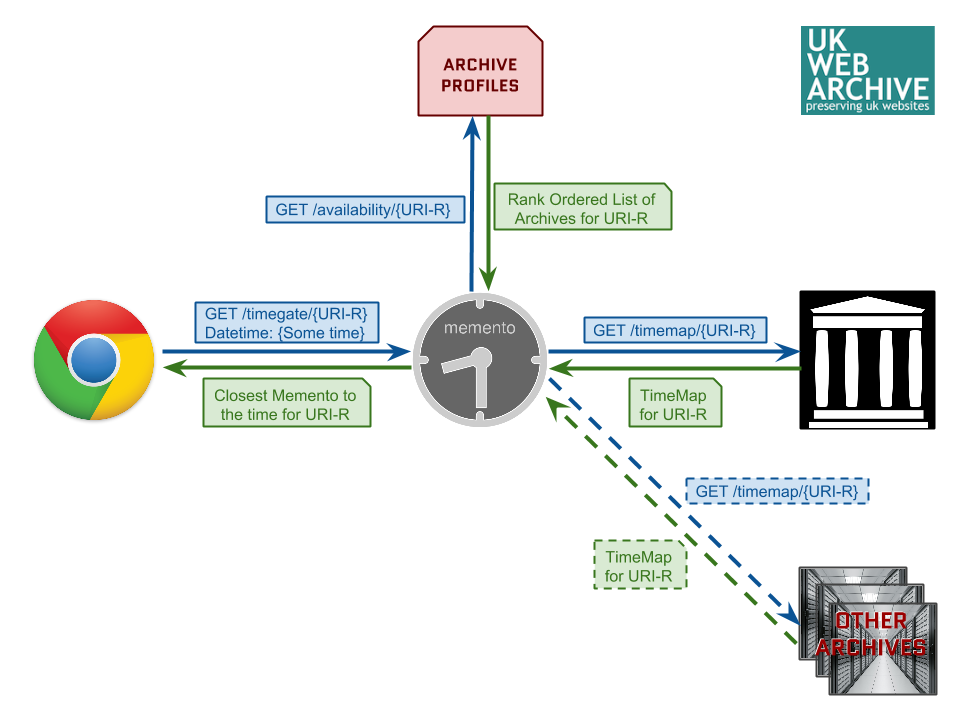
Available Profiling Resources
- Client request
- Archive response
- Archive index (CDX files)
A Client Request
- Canonical URL
- Accept-Datetime (optional)
- Accept-Language (optional)
GET /timegate/http://www.cnn.com/ HTTP/1.1
Host: mementoweb.org
Accept: text/html,application/xhtml+xml;q=0.9,image/webp,*/*;q=0.8
Accept-Encoding: gzip, deflate, sdch
Accept-Datetime: Sat, 16 Jun 2012 00:00:00 GMT
Accept-Language: en-US,en;q=0.8
Cache-Control: max-age=0
If-Modified-Since: Thu, 23 Apr 2015 16:51:50 GMT
If-None-Match: "7ff8-5146718929580"
Connection: keep-alive
Cookie: __unam=34c3c7d-14ce917ce62-43c38e5e-7...
User-Agent: Mozilla/5.0 Linux x86_64 Chrome/42.0.2311.90 ...
An Archive Response
- Canonical URL (known)
- Memento-Datetime
- Original Content-Language (optional)
HTTP/1.1 200 OK
Server: Tengine/2.0.3
Date: Sun, 26 Apr 2015 00:25:57 GMT
Content-Type: text/html;charset=utf-8
Content-Length: 85945
Connection: keep-alive
set-cookie: wayback_server=37; Domain=archive.org; Path=/; Expires=Tue, 26-May-15 00:25:57 GMT;
Memento-Datetime: Sat, 25 Apr 2015 13:38:16 GMT
Link: ; rel="original", ; rel="timemap"; type="application/link-format", ; rel="timegate", ; rel="last memento"; datetime="Sat, 25 Apr 2015 13:38:16 GMT", ; rel="first memento"; datetime="Tue, 02 Dec 2003 22:47:49 GMT", ; rel="prev memento"; datetime="Sat, 25 Apr 2015 12:37:09 GMT"
X-Archive-Guessed-Charset: UTF-8
X-Archive-Orig-via: 1.1 varnish, 1.1 varnish, 1.1 varnish
X-Archive-Orig-content-language: en
X-Archive-Orig-x-content-type-options: nosniff
X-Archive-Orig-vary: Accept-Encoding,Cookie
X-Archive-Orig-content-type: text/html; charset=UTF-8
X-Archive-Orig-cache-control: private, s-maxage=0, max-age=0, must-revalidate
X-Archive-Orig-server: Apache
X-Archive-Orig-x-ua-compatible: IE=Edge
X-Archive-Orig-x-powered-by: HHVM/3.3.1
X-Archive-Orig-x-cache: cp1055 hit (8), cp4008 hit (2), cp4018 frontend hit (2260)
X-Archive-Orig-date: Sat, 25 Apr 2015 13:38:16 GMT
X-Archive-Orig-x-varnish: 2071318289 2071318130, 3622373035 3622372966, 2583078312 2582646855
X-Archive-Orig-x-analytics: page_id=15580374;ns=0
X-Archive-Orig-age: 425
X-Archive-Orig-last-modified: Sat, 25 Apr 2015 13:31:10 GMT
X-Archive-Orig-connection: close
X-Archive-Wayback-Perf: {"IndexLoad":255,"IndexQueryTotal":255,"RobotsFetchTotal":2,"RobotsRedis":1,"RobotsTotal":15,"Total":378,"WArcResource":65}
X-Archive-Playback: 1
X-Page-Cache: MISS
A CDX Snippet
- Canonical URL
- Memento Datetime
cnn.com/ 20080226193757 http://www.cnn.com/ text/html 200 2Q4OZSVKPZMUF36UN6FBXFNGDKARPA7N - - 10368892 ARCHIVEIT-1022-MOLLYASTRID-CASTRORESI-20080226193719-00000-crawling10.us.archive.org.arc.gz
cnn.com/ 20090314024036 http://www.cnn.com/ text/html 200 4PVCGT22VVTDJ3GXIJEUZ3JOJ4HBZYB4 - - 13282500 ARCHIVEIT-1023-20090314024015-00058-crawling105.us.archive.org.warc.gz
cnn.com/ 20090314024036 http://www.cnn.com/ text/html 200 4PVCGT22VVTDJ3GXIJEUZ3JOJ4HBZYB4 - - 24595360 ARCHIVEIT-1023-20090314024003-00057-crawling105.us.archive.org.arc.gz
i.cdn.travel.cnn.com/ 20130102083554 http://i.cdn.travel.cnn.com/ text/html 200 D2MJUR62VJ5D6CNL5PUDQFEW4GIRGIX2 - - 33901711 ARCHIVEIT-1023-QUARTERLY-UGGVZU-20130102080252-00007-wbgrp-crawl063.us.archive.org-6682.warc.gz
i.cdn.travel.cnn.com/ 20130404172913 http://i.cdn.travel.cnn.com/ text/html 200 JZKL7HGGBN73BUXFISEJLM7YNAXE7MTI - - 274508081 ARCHIVEIT-1023-QUARTERLY-5885-20130404074716948-00002-wbgrp-crawl067.us.archive.org-6443.warc.gz
Complete URI-R Profiling
- Sanderson et al. created a URIR profile for various archives
- Extracted every URI-R from all the CDX files
- Gained complete knowledge of the holding of the participating archives
- Profiles were huge
- Difficult to keep up-to-date
- Misses URI-Rs added later in the archive
TLD-only Profiling
- AlSum et al. created a TLD profile for various archives
- Collected statistics about various archives on various TLDs
- Lightweight profiles
- Lots of false-positives
- All the ".com" queries will be routed to an archive that has only a few URI-Rs with ".com" TLD
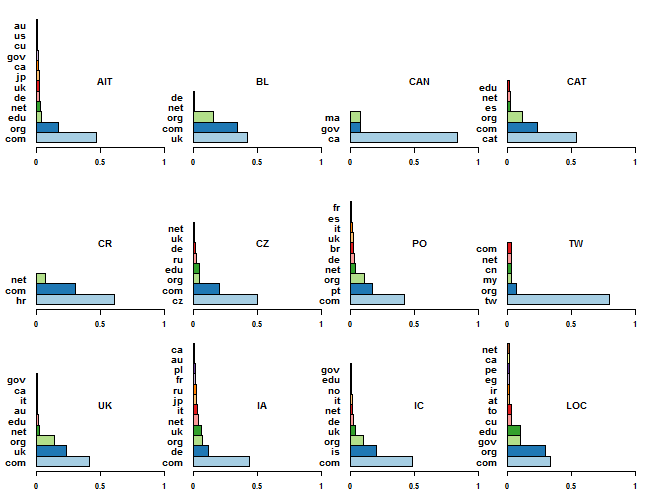
Middle Ground
- Partial URI-Rs, such as:
- Registered domain name
- Complete domain name (along with any sub-domains)
- Complete domain name and first few path segments
- Registered domain name and counts of other segments such as sub-domain, path, and query parameter
- Combining above with other attributes such as Content-Language and Memento-Datetime
Archive Profile
- High-level digest of an archive
- Predicts presence of mementos of a URI-R in an archive
- Provides various statistics about the holdings
- Small in size
- Publicly available
- Easy to update and partially patch
- Useful for Memento query routing and other things
Structure
Archive metadata
Statistics:
Profile types:
Keys: Frequency measurements
Profile types
- URI-R based
- Complete URI-R
- TLD only
- URI-R hashes, such as:
- Only first few segments of the URI-R (Sub-URI)
- Registered domain name along with counts of other segments (Segment-Digest)
- Language
- Datetime
- Many more...
Keys
- Depend on the profile type
- Control the balance between profile size and details
URI-R : "bbc.co.uk/images/Logo.png?height=80&width=200"
TLD : ".uk"
Sub-URI : "uk)/", "uk,co)/", "uk,co,bbc)/", "uk,co,bbc)/images"
Seg-Digest : "0/bbc.co.uk/4"
Language : "en-GB"
Datetime : "201403" # YYYYMM
Frequency Measurements
- Can have the same structure for all profile types
- Flexible to choose the attribute set to be included
- Affects the profile complexity
- Predicts the presence of the mementos of a URI-R
"uk,co,bbc)/":
urim:
max: 2
min: 1
total: 128
urir: 115
Horizontal and Vertical Holdings
"uk,co,bbc)/":
urim:
max: 100
min: 100
total: 100
urir: 1
"uk,co,bbc)/":
urim:
max: 1
min: 1
total: 100
urir: 100
"uk,co,bbc)/":
urim:
max: 20
min: 5
total: 100
urir: 10
Sample Profile
---
"@context": "https://oduwsdl.github.io/context/archprofile.jsonld"
"@id": "http://www.webarchive.org.uk/ukwa/"
about:
accesspoint: "http://www.webarchive.org.uk/wayback/"
mechanism: "http://oduwsdl.github.io/terms/mechanism#cdx"
name: "UKWA 1996 Collection"
profile_updated: "2015-01-20T17:25:30Z"
suburi_class: "http://oduwsdl.github.io/terms/suburi#H3P1"
more_meta_data: "..."
stats:
language:
"en-US":
urim: {max: 13, min: 1, total: 47529}
urir: 25621
"more_languages": "..."
suburi:
"uk)/":
urim: {max: 8, min: 1, total: 932432}
urir: 867817
"uk,co)/":
urim: {max: 8, min: 1, total: 410979}
urir: 378686
"uk,co,bbc)/":
urim: {max: 2, min: 1, total: 128}
urir: 115
"uk,co,bbc)/images":
urim: {max: 1, min: 1, total: 3}
urir: 3
"more_suburis": "..."
time:
"199603":
urim: {max: 5, min: 1, total: 124}
urir: 62
"more_dates": "..."
urim: {max: 1185, min: 1, total: 934747}
urir: 868513
URI-R Based Profiles
-
URI-R preprocessing
- Canonicalize
- Apply SURT
- Split segments
- Extract registered domain
- Count segments (sub-domain, path, query params)
-
Generate all Sub-URIs
- Incrementally add segments from left-to-right
- Only up to max host and path segments config
- Create Segment-Digest with registered domain
- Prefix sub-domain count
- Suffix path and query params count
Key Generation
Intermediate Values
{canonical_url: "bbc.co.uk/images/Logo.png?height=80&width=200",
surt_url: "uk,co,bbc)/images/Logo.png?height=80&width=200",
reg_domain: "bbc.co.uk", path_initial: "i",
subdomain_count: 1, path_count: 2, query_params_count: 2}
Sub-URI(HP)
["uk)/",
"uk,co)/",
"uk,co,bbc)/",
"uk,co,bbc)/images"]
SegDigest(include_path_initial)
"1/bbc.co.uk/i4"
Implementation
-
GitHub:/oduwsdl/suburi_generator
- A python module to generate Sub-URIs from SURT
-
GitHub:/oduwsdl/archive_profiler
- Various profile generation scripts
Canonicalization
- Remove "http(s)", "www", and fragment of a URI
- Downcase hostname
- Remove some known query paras e.g., "jsessionid"
- Sort query params by keys and values (secondary)
URL = "https://www.BBC.co.uk/images/Logo.png?width=200&height=80#f"
Canonicalize(URL)
#=> "bbc.co.uk/images/Logo.png?height=80&width=200"
Sort-friendly URI Reordering Transform (SURT)
- Take canonical URL as input
- Join hostname segments by commas in reverse order
- Separate hostname and path by closing parenthesis
Can_URL = "bbc.co.uk/images/Logo.png?height=80&width=200"
SURT(Can_URL)
#=> "uk,co,bbc)/images/Logo.png?height=80&width=200"
Sub-URI
- Take SURT URL as input
- Incrementally add segments from left-to-right one-by-one
- Stop if hostname or path segment limit policy reaches
- Return the list of all Sub-URIs
SURT_URL = "uk,co,bbc)/images/Logo.png?height=80&width=200"
SubURI(SURT_URL, policy="H3P1")
#=> ["uk)/",
# "uk,co)/",
# "uk,co,bbc)/",
# "uk,co,bbc)/images"]
URL to Sub-URI
URL = "https://www.BBC.co.uk/images/Logo.png?width=200&height=80#f"
Can_URL = Canonicalize(URL)
#=> "bbc.co.uk/images/Logo.png?height=80&width=200"
SURT_URL = SURT(Can_URL)
#=> "uk,co,bbc)/images/Logo.png?height=80&width=200"
Sub_URIs = SubURI(SURT_URL, policy="H3P1")
#=> ["uk)/",
# "uk,co)/",
# "uk,co,bbc)/",
# "uk,co,bbc)/images"]
Segment Count Digest
- Extract registered domain name and initial letter of path
- Count sub-domain and trailing (path + query) segments
- Serialize as follows:
{subdomain_count}/{reg_domain}/{path_initial}?{trailing_count}
URL = "https://www.BBC.co.uk/images/Logo.png?width=200&height=80#f"
Segments = Segmentize(URL)
#=> {reg_domain: "bbc.co.uk",
# path_initial: "i",
# subdomain_count: 1,
# path_count: 2,
# query_params_count: 2,
# trailing_count: 4}
SegDigest(Segments, policy="exclude_path_initial")
#=> "1/bbc.co.uk/4"
SegDigest(Segments, policy="include_path_initial")
#=> "1/bbc.co.uk/i4"
JSON Serialization
- Can have complex nested data structure
- JSON-LD for linked data
- No partial key lookup
- Unsuitable for text processing tools
- Allows processing only when fully loaded
- A single malformed character makes it unparsable
- Difficult to patch
{
"suburi": {
"uk)/": {
"urim": {
"max": 8,
"min": 1,
"total": 932432
},
"urir": 867817
},
"uk,co)/": {
"urim": {
"max": 8,
"min": 1,
"total": 410979
},
"urir": 378686
},
"uk,co,bbc)/": {
"urim": {
"max": 2,
"min": 1,
"total": 128
},
"urir": 115
},
"uk,co,bbc)/images": {
"urim": {
"max": 1,
"min": 1,
"total": 3
},
"urir": 3
}
}
}
CDX-JSON Serialization
- Fusion of CDX and JSON file formats
- A key followed by strict single line JSON value
- Unlike CDX, values can have arbitrary attributes
- Text processing tool friendly
- No single root node or single document restrictions
- Enables binary search
- Enables partial key lookup
- Error resilient
@context "https://oduwsdl.github.io/contexts/archiveprofile.jsonld"
@id "http://www.webarchive.org.uk/ukwa/"
@about {"name": "UKWA 1996 Collection", "type": "suburi#H3P1", "...": "..."}
uk)/ {"urim": {"max": 8, "min": 1, "total": 932432}, "urir": 867817},
uk,co)/ {"urim": {"max": 8, "min": 1, "total": 410979}, "urir": 378686},
uk,co,bbc)/ {"urim": {"max": 2, "min": 1, "total": 128}, "urir": 115},
uk,co,bbc)/images {"urim": {"max": 1, "min": 1, "total": 3}, "urir": 3}
Merging
- Only process new data to periodically update for freshness
- Parallel processing
- Difficult to keep detailed measures with absolute values
- Derived simple heuristic measures to predict presence of mementos
Merging Example
Base Profile
com,cnn)/ {"urir_sum": 30, "sources": 1},
uk,co,bbc)/ {"urir_sum": 20, "sources": 1}
New Profile
com,cnn)/ {"urir_sum": 10, "sources": 1},
com,usatoday)/ {"urir_sum": 5, "sources": 1}
Merged Profile
com,cnn)/ {"urir_sum": 40, "sources": 2},
uk,co,bbc)/ {"urir_sum": 20, "sources": 1},
com,usatoday)/ {"urir_sum": 5, "sources": 1}
Dataset
- Two archives
- Three sample query sets
- Various profiles for each archive and sample set
Archives
| Archive | URI-Rs | URI-Ms | Size |
|---|---|---|---|
| Archive-It | 1.9B | 5.3B | 1.8TB |
| UKWA | 0.7B | 1.7B | 0.5TB |
Sample Query Sets
| Sample | Size | In Archive-It | In UKWA |
|---|---|---|---|
| DMOZ | 100,000 | 4,042 | 1,896 |
| MementoProxy | 100,000 | 4,222 | 193 |
| IAWayback | 100,000 | 3,999 | 275 |
Evaluation
- Relate CDX Size, URI-M, URI-R, and Sub-URI
- Analyze profile growth
- Estimate Relative Cost
- Evaluate Routing Precision vs. Relative Cost
$\text{Relative Cost} = \frac{|\text{Keys in the Profile}|}{|\text{URI-R in the Archive}|}$
$\text{Routing Precision}=\frac{|\text{URI-R Present in the Archive}|}{|\text{URI-R Predicted by the Profile in Archive}|}$
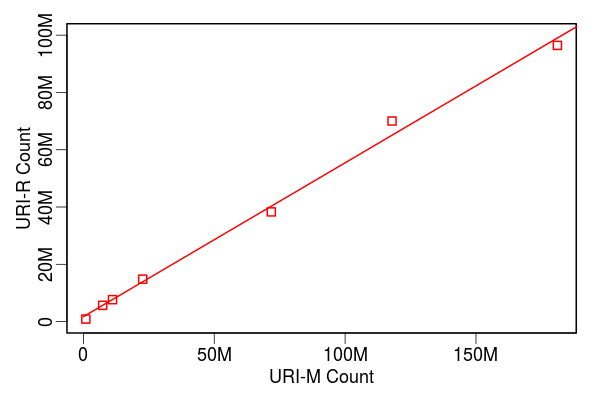
UKWA Dataset
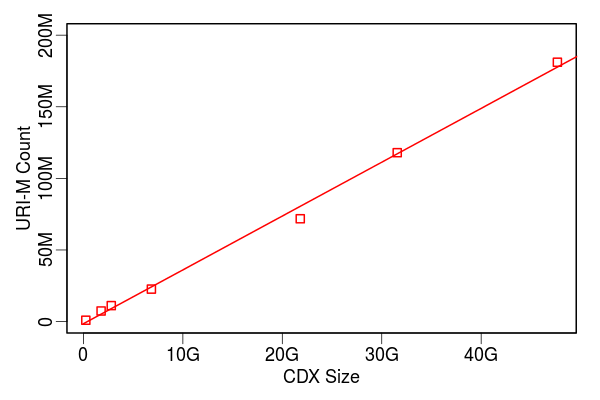
- Yearly data as seprate collections
- Average CDX line size: 275 bytes
- URI-M/URI-R ratio: 2.46
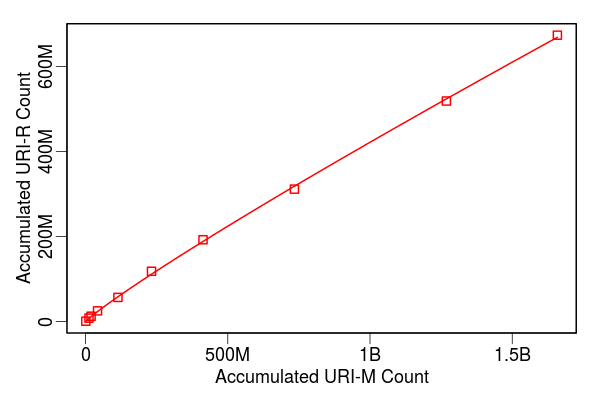
Accumulated URI-R Growth (UKWA)
- Successive yearly data was merged
-
Follows Heaps' Law
$C_r = K C_m ^ \beta$
- K = 3.897
- β = 0.892
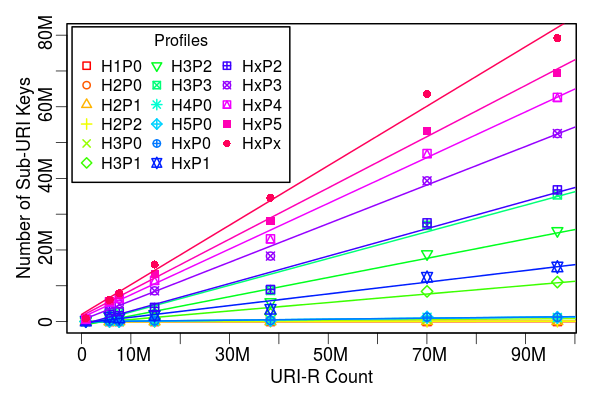
Sub-URI Key Growth (UKWA)
- Slope of the fit line is the Relative Cost for the profile policy
- Complete URI-R profile has Relative Cost 1
Cost Analysis
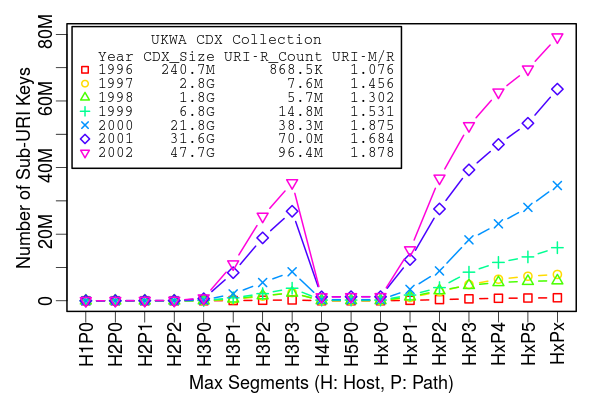
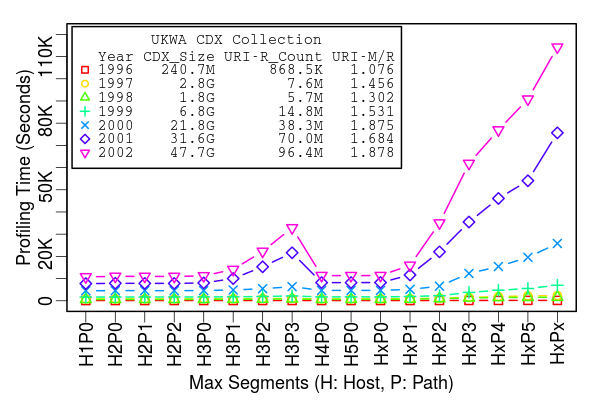
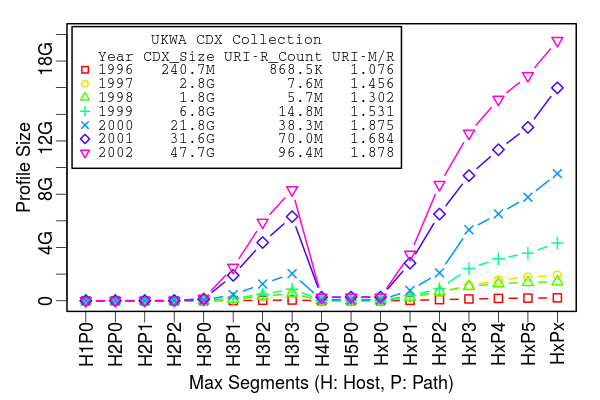
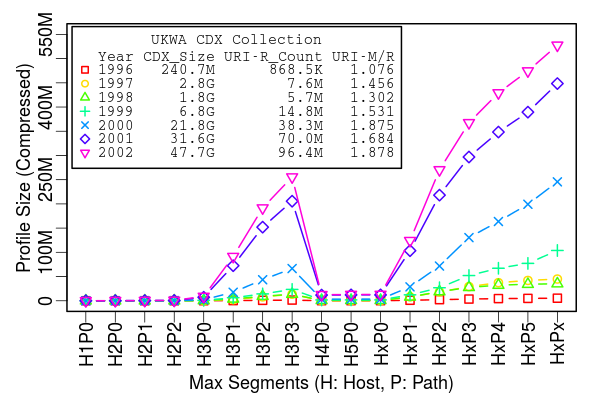
Search Precision of Various Profiles
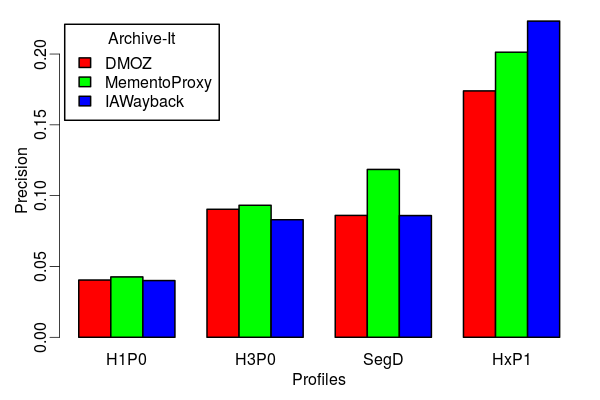
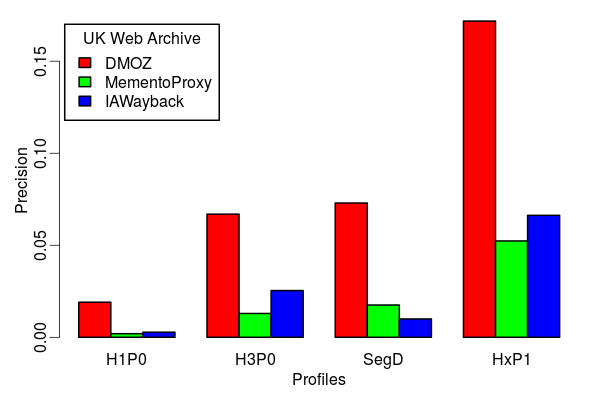
-
Search Precision wrt TLD-only profile
- Double for H3P0
- Five fold for HxP1
- Segment-Digest is as good as H3P0
Relative Cost vs. Search Precision
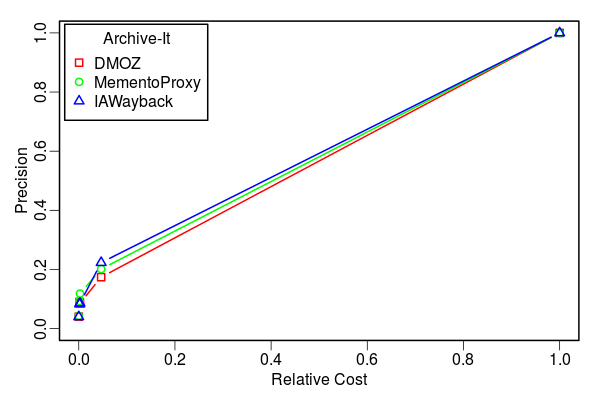
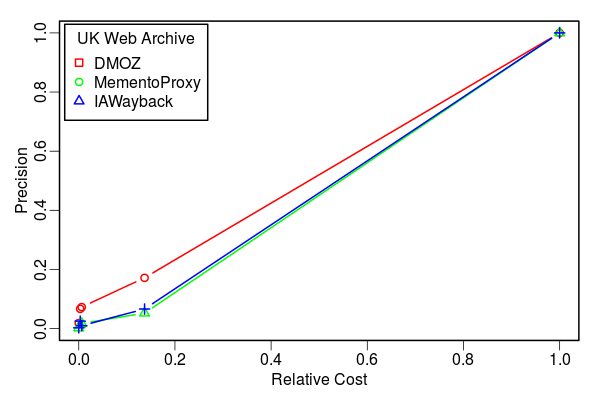
- Up to 22% routing precision with <5% Reltive Cost
- <0.3% sample URIs from MementoProxy and IAWayback logs present in UKWA
- Shallow crawling of UKWA results in higher cost
Relative Profile Cost (UKWA)
| Profile | Cost | Profile | Cost | Profile | Cost |
|---|---|---|---|---|---|
| H1P0 | 3.2e-06 | H3P2 | 0.26823 | HxP2 | 0.38313 |
| H2P0 | 0.00027 | H3P3 | 0.37343 | HxP3 | 0.53928 |
| H2P1 | 0.00059 | H4P0 | 0.01348 | HxP4 | 0.63889 |
| H2P2 | 0.00099 | H5P0 | 0.01388 | HxP5 | 0.71568 |
| H3P0 | 0.00862 | HxP0 | 0.01401 | HxPx | 0.83107 |
| H3P1 | 0.11864 | HxP1 | 0.16349 | URIR | 1.00000 |
Future Work
- Generating sample URI sets
- Profiling via sampling
- Language profiles
- Evaluation of combination profiles such as Sub-URI along with Datetime
- Profiles for usage other than Memento routing, such as,
- Media-type profiles (e.g., images, pdf, audio etc.)
- Site classification based profiles (e.g., news, wiki, social media, blog etc.)
Conclusions
- Generated profiles with different policies for two archives
- Examined cost-accuracy trade-offs of various profiles
- Related CDX Size, URI-M, URI-R, and Sub-URI
- Gained up to 22% routing precision with <5% relative cost without any false negatives
- <5% of the queried URIs are present in each of the individual archives
-
Implementation codes are available at:
- GitHub:/oduwsdl/suburi_generator
- GitHub:/oduwsdl/archive_profiler
