


Automating the Testing Oracle
Steven J Zeil
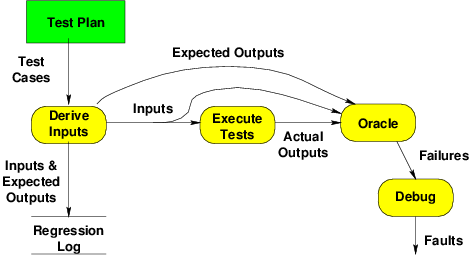
Earlier we introduced this model of the basic testing process.
In this lesson, we turn our attention to the oracle, the process for determining whether a test has failed.
We will argue that the economics of testing provide a powerful incentive to automate the oracle. Traditionally, this has been done by capture-and-examine, capturing outputs and then using a separate automated process to examine and pass judgement upon those outputs.
Current practice, however, emphasizes self-checking tests, drivers that both feed input to the code under test and immediately evaluating its responses. Self-checking tests are supported by a *Unit framework. We will look at popular frameworks for both Java and C++.
1 Automating the Oracle
Why Automate the Oracle?
-
Most of the effort in large test suites is evaluating correctness of outputs
-
The oracle is a decision procedure for deciding whether the output of a particular test is correct.
-
Humans (“eyeball oracles”) are notoriously unreliable
-
better to have tests check themselves.
-
-
Regression test suites can be huge.
Thousands, tens of thousands, even hundreds of thousands of tests are not unheard of. If your idea of testing is running some code and visually inspecting the output, you can see that won’t work on this kind of scale. Regression tests have almost always been designed to check themselves. Often this was done by recording, during unit, integration, or systems test, the outputs produced by each test input. During regression testing, the same inputs are rerun, and the outputs compared to the earlier ones that had been recorded. If the outputs change, an alert is printed. If the outputs stay the same, testing moves quietly on to the next test.
-
Modern development methods emphasize rapid, repeated unit tests
It might not be obvious that self-checking is quite valuable for unit and integration testing as well. But if test outputs have to be inspected by a human, then anything more than a very few tests becomes a tedious thing to do. This motivates programmers to write very few tests and to run them infrequently, both of which are very bad ideas.
- Test-driven development: Develop the tests first, then write the code.
In fact, many of the latest trends in software development place a lot more emphasis on almost continual unit testing. In so-called agile or extreme programming, programmers are expected to write tests before implementing their functions or ADTs, and to continually rerun the tests as unit are added or changed. (In effect, we get a kind of “rolling” integration test.)
In continuous integration processes, every time a programmer stops work on a unit, not only are its unit tests run, but the changes are automatically integrated into the entire program, and integration and systems tests are re-run.
But that’s just not going to happen if testing is hard to do.
%endif
- Test-driven development: Develop the tests first, then write the code.
-
Debugging: if you can’t reproduce the error, how will you know when you’ve fixed it?
If a bug is reported or a new feature requested, the first step is to add new tests that fail because of the bug or missing feature. Then we will know we have successfully fixed the problem when we are able to pass that test.
The best way to be sure programmers rerun the tests on a regular basis is to make the test run part of the regular build process (e.g., build the test runs into the project
makefile) and to make them self-checking.
1.1 How can oracles be automated?
Output Capture
If we are doing systems/regression tests, the first step towards automation is to capture the output:
If a program produces output files, one can self-check by creating a file representing the expected correct output, then running the program to get the actual output file and using a simple comparison utility like the Unix diff or cmp commands to see if the actual output is identical to the expected output.
For system-level regression tests, this is even simpler. Once we have a program that passes our system tests, we run it on those tests and save the outputs. Those become the expected output files for later regression testing. (Remember, the point of regression testing is to determine if any behavior has changed due to recent updates to the code.)
If the program updates a database, it may be possible to capture entire databases in a similar fashion. Alternatively, we write database queries to check for changes in the records most likely to have been affected by a test.
On the other hand, if the program’s main function is to present information on a screen, self-checking is very difficult. Screen captures are often not much use, because we are unlikely to want to deal with changes where, say one window is a pixel wider or a pixel to the left of where it had been in a prior test. Self-checking tests for programs like this either require extremely fine control over all possible interactive inputs and graphics device characteristics, or they require a careful “design for testability” to record, in a testing log file, information about what is being rendered on the screen. (We’ll revisit this idea later in the semester when we discuss the MVC pattern for designing user interfaces.)
Output Capture and Drivers
At the unit and integration test level, we are testing functions and ADT member functions that most often produce data, not files, as their output. That data could be of any type.
How can we capture that output in a fashion that allows automated examination?
-
Traditional answer is to rely on the scaffolding to emit output in text form.
-
A more sophisticated answer, which we will explore later, is to design these tests to be self-checking.
1.2 Examining Output
1.2.1 File Tools
diff,cmpand similar programs compare two text files byte by byte- used to compare expected and actual output
- useful in back-to-back testing of
- old system to its new replacement
- system before and after a bug repair
- but also used with manually generated expected output
- parameters allow special treatments of blanks, empty lines, etc.
- some versions can be used with binary files
Alternatives
- More sophisticated tests can be performed via
grepand similar utilities- search file for data matching a regular expression
Custom oracles
-
Some programs lend themselves to specific, customized oracles
- For example, a program to invert a matrix can be checked by multiplying its input and output together — should yield the identity matrix.
-
pipe output from program/driver directly into a custom evaluation program, e.g.,
testInvertMatrix matrix1.in > matrix1.out multiplyCheck matrix1.in < matrix1.outor
testInvertMatrix matrix1.in | multiplyCheck matrix1.in -
Most useful when oracle can be written with considerably less effort than the program under test
1.2.2 expect
expect is a shell for testing interactive programs.
- an extension of
TCL(a portable shell script).
Key expect Commands
-
spawn: Launch an interactive program. -
send: Send a string to a spawned program, simulating input from a user. -
expect: Monitor the output from a spawned program. Expect takes a list of patterns and actions:pattern1 {action1} pattern2 {action2} pattern3 {action3} ⋮and executes the first action whose pattern is matched.
- Patterns can be regular expressions or simpler “glob” patterns
-
interact: Allow person running expect to interact with spawned program. Takes a similar list of patterns and actions.
Sample Expect Script
Log in to other machine and ignore “authenticity” warnings.
#!/usr/local/bin/expect
set timeout 60
spawn ssh $argv
while {1} {
expect {
eof {break}
"The authenticity of host" {send "yes\r"}
"password:" {send "$password\r"}
"$argv" {break} # assume machine name is in prompt
}
}
interact
close $spawn_id
Expect: Testing a program
puts "in test0: $programdir/testsets\n"
catch {
spawn $programdir/testsets ➀
expect \ ➁
"RESULT: 0" {fail "testsets"} \ ➂
"missing expected element" {fail "testsets"} \
"contains unexpected element" {fail "testsets"} \
"does not match" {fail "testsets"} \
"but not destroyed" {fail "testsets"} \
{RESULT: 1} \{pass "testsets"} \ ➃
eof {fail "testsets"; puts "eofbsl nl"} \
timeout {fail "testsets"; puts "timeout\n"}
}
catch {
close
wait
}
-
➀ Launches the
testsetsprogram -
➁ Watches the output for one of the following conditions
-
➂ The “RESULT” line is the normal output. A result of 0 is a test case failure.
-
➃ A result of 1 is a test case success
-
-
The various other options are diagnostic/error messages that could appear if the program never reaches the RESULT output.
1.3 Limitations of Capture-and-Examine Tests
Structured Output
For unit/integration test, output is often a data structure.
-
Data must be serialized to generate text output and then parsed to read the subsequent input
-
A lot of work
- Easy to omit details
- Can introduce bugs of its own
-
Similar issues can exist with the need to supply structured inputs
Repository Output
For system and high-level unit/integration tests, output may be updates to a database or other repository.
- Must be indirectly “captured” via subsequent query/access
- significant setup and cleanup effort per test
- need separate test stores
Graphics Output
-
For system and high-level unit/integration tests, output may be graphics
- very hard to capture
-
Similar issues can arise supplying GUI input
- Supplying a repeatable sequence of input events (key presses, mouse movement & clicks, etc)
- Sometimes timing-critical
2 Self-Checking Unit & Integration Tests
-
Addresses problem of capture-and-examine for structured data
-
Each test case is a function.
- That function constructs required inputs …
- and passes those inputs to the module under test …
- and examines the output …
-
… all within the memory space of the running function
In testing an ADT, we are not testing an individual function, but a collection of related functions. In some ways that makes thing easier, because we can use many of these functions to help test one another.
2.1 First Cut at a Self-Checking Test
Suppose you were testing a SetOfInteger ADT and had to test the add function in isolation, you would need to know how the data was stored in the set and would have to write code to search that storage for a value that you had just added in your test. E.g.,
void testAdd (SetOfInteger aSet)
{
aSet.add (23);
bool found = false;
for (int i = 0; i < aSet.numMembers && !found; ++i)
found = (aSet[i] == 23);
assert(found);
}
2.1.1 What’s Good and Bad About This?
void testAdd (SetOfInteger aSet)
{
aSet.add (23);
bool found = false;
for (int i = 0; i < aSet.numMembers && !found; ++i)
found = (aSet.data[i] == 23);
assert(found);
}
-
Good: captures the notion that 23 should have been added to the set
-
Good: requires no human evaluation
-
Bad: relies on underlying data structure
- Requires the tester to think at multiple levels of abstraction
- Test is fragile: if implementation of SetOfInteger changes, test can become useless
- Might not even compile - those data members are probably private
2.2 Better Idea: Test the Public Functions Against Each Other
On the other hand, if you are testing the add and the contains function, you could use the second function to check the results of the first:
void testAdd (SetOfInteger aSet)
{
aSet.add (23);
assert (aSet.contains(23));
}
-
Simpler
-
Robust: tests remain valid even if data structure changes
-
Legal: Does not require access to
privatedata
Not only is this code simpler than writing your own search function as part of the test driver, it continues to work even if the data structure used to implement the ADT should be changed. What’s more, it is, in a sense, a more thorough test, since it tests two functions at once. Finally, there’s the simple fact that the test with the explicit loop probably won’t even compile, since it refers directly to data members that are almost certainly private.
In a sense, we have made a transition from white-box towards black-box testing. The new test case deliberately ignores the underlying structure.
2.2.1 Idiom: Preserve and Compare
void testAdd (SetOfInteger startingSet)
{
SetOfInteger aSet = startingSet;
aSet.add (23);
assert (aSet.contains(23));
if (startingSet.contains(23))
assert (aSet.size() == startingSet.size());
else
assert (aSet.size() == startingSet.size() + 1);
}
Note that we
- save the original ADT value, then
- modify a copy, and then
- compare the original and copy to see the changes
2.2.2 More Thorough Tests
You can see the usefulness of “preserve and comapre” in this more thorough test.
void testAdd (SetOfInteger aSet)
{
for (int i = 0; i < 1000; ++i)
{
int x = rand() % 500;
bool alreadyContained = aSet.contains(x);
int oldSize = aSet.size();
aSet.add (23);
assert (aSet.contains(x));
if (alreadyContained)
assert (aSet.size() == oldSize);
else
assert (aSet.size() == oldSize + 1);
}
}
2.3 assert() might not be quite what we want
Our use of assert() in these examples has mixed results
-
Good: stays quiet as long as we are passing tests
- failures easily detected by humans
-
Bad: testing always stops at the first failure
- In a large suite of many such test cases, we may be missing out on info that would be useful for debugging
-
Bad: diagnostics are limited to file name and line number where the assertion failed.
All of what we have shown in this lesson is a lot of work, but represents what programmers did on a regular basis until unit testing frameworks became popular. These frameworks are the subject of the next lesson/