


Projects & Architectures
Thomas J. Kennedy
A Software Architecture is a collection of decisions that apply globally across the entire set of subsystems of a large project.
1 Perspective
1.1 Consider Design…
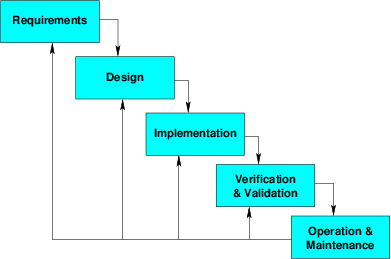
… back in the “gold old days” of WaterFall.
A classic division would be
- High level design
-
Dividing the system into modules.
-
- Low-Level Design
- Selecting the data structures and algorithms for a specific module.
1.2 Too Many Cooks…

The High/Low division suggests that once high-level design is completed, different developers can work in complete independence.
- Things are rarely that simple.
- Some decisions need to be shared.
1.2.1 An Alternate Breakdown of Design
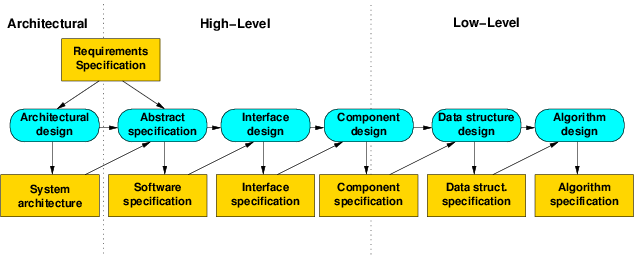
- The diagram here suggests a fairly document-heavy process typical of Waterfall.
1.3 Architectural Design
The collection of decisions that need to be common to all components.
Examples of architectural design decisions would be
- Will the system run on a single machine or be distributed over multiple CPUs?
- Will outputs be stored in a file or in a database?
- How will run-time errors be handled?
Even as process models other than Waterfall have become more common, the importance of architectural design has remained.
1.4 Towards Incremental Processes
1.4.1 Iterative Development
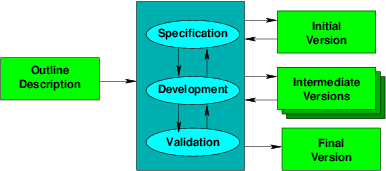
- A variety of related approaches
- a counter-reaction to what many believe to be an overly rigid, management-focused, waterfall model
- emphasize quick cycles of development, usually with earlier and more user-oriented validation
- Requirements specification, design and implementation are interleaved.
- Each version adds a small amount of additional functionality.
As a counter-reaction to what many believe to be an overly rigid waterfall model, there are a variety of incremental approaches that emphasize quick cycles of development, usually with earlier and more user-oriented validation.
There is a greater emphasis on producing intermediate versions, each adding a small amount of additional functionality. Some of these are releases, either external (released outside the team) or internal (seen only by the team), which may have been planned earlier.
1.4.2 Incremental Development
-
“Iterative” means that we can re-visit decisions, design, and code produced in earlier iterative steps.
-
“Incremental” means that each iteration produces a small unit of additional functional behavior.
- Something that can be demonstrated.
- Something that works now, but wasn’t working before.
We don’t try to build major subsystems of the project in a single pass.
-
This often requires a more “vertical” view in which we implement a bit of high level control code and pieces of related low-level code.
-
As opposed to the “horizontal” approach of working “bottom up” and implementing the low-level ADTS, then the code that calls, upon them, then …, ending with the top-level interface of the whole program.
-
Or the “horizontal” approach of working “top down” and implementing the most abstract code (the GUI or command-line interfaces), then functions that they call, then the … ending with the lowest-level ADTS that don’t call on anything else.
Iterative versus Incremental Models
-
Iterative – we do some set of process steps repeatedly.
To use a programming analogy, this is iterative:
while (!done) { ⋮ } -
Incremental – we accumulate value in small steps.
To use a programming analogy, this is incremental:
total += x;
Incremental development is almost always iterative, but you can be iterative without being incremental.
1.4.3 Keeping Iterative Development on Track
-
We need a “signpost” - non-local information.
-
Even in incremental development, that’s the role of architecture.
2 Software Architecture
2.1 Dimensions of Software Architecture
- Primary Interface
- Deployment
- Error handling
- Data Storage
- Modular structure
This is my own listing – I have not seen this notion of dimensions addressed elsewhere.
2.1.1 Primary Interface
- CLI
- Protocol
- GUI
- Application
- Web-based
- API (library)
2.1.2 Deployment
- Single machine
- Distributed
2.1.3 Error Handling
- Throwing exceptions or shut down,
- console or pop-up messages
- logging
2.1.4 Data Storage
- Centralized or distributed
- database or files
2.1.5 Modular structure
- Which modules are allowed to interact with which other modules?
- What limitations are placed on dependencies between modules?
3 Common Architectural Patterns
3.1 Pipes & Filters
a.k.a. Data Flow models
dimensions: modular structure (but not deployment)
- System is described as a graph of components passing data to one another.
3.1.1 Example: Compilers
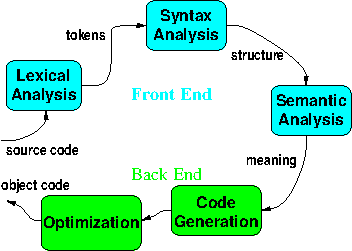
3.1.2 Example: Extract
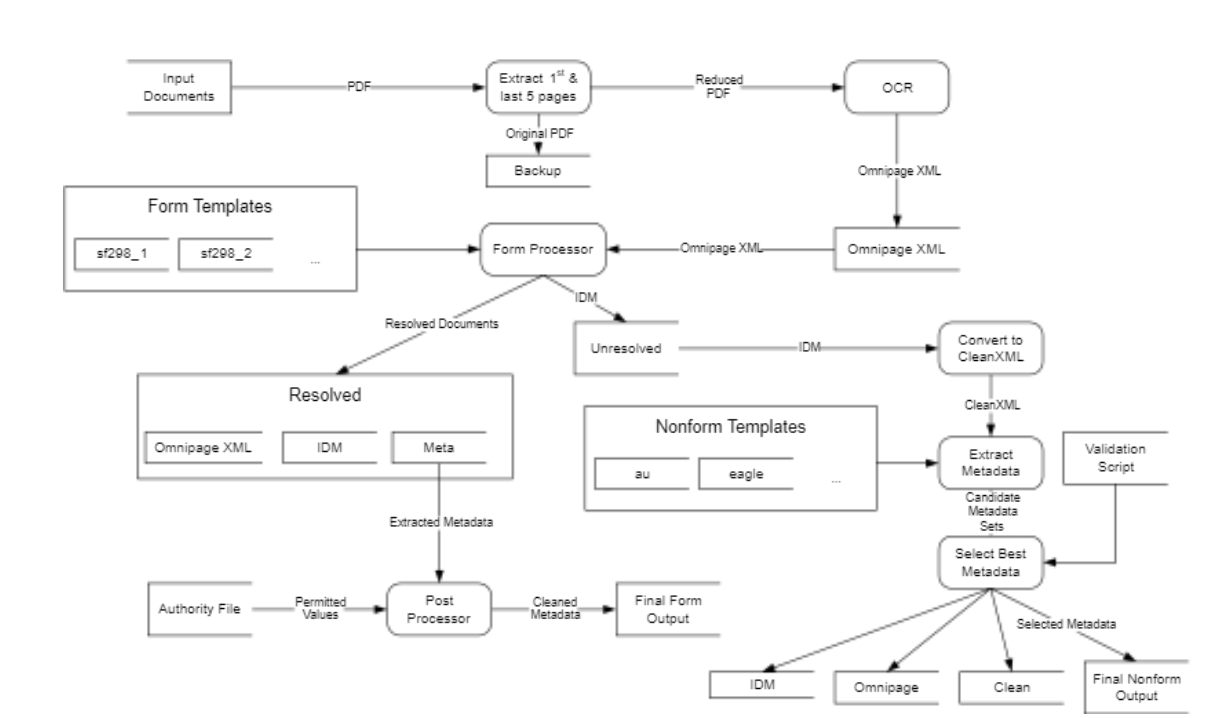
Extract (Maly, Zeil, Zubair, 2005-2010) was a system for extracting metadata from PDF documents submitted to the Defense Technical Information Center, NASA, and the US Government Printing Office.
3.2 Blackboard
dimensions: storage
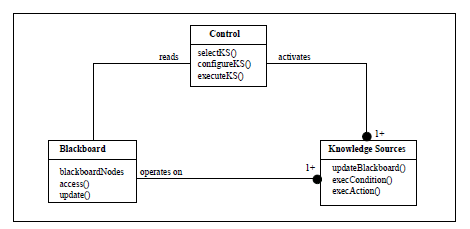
The blackboard architecture was popular for A.I. projects and expert systems.
-
e.g., Hearsay-II, an early speech recognition system
-
It focuses on a collection of independent processes coupled though a monolithic storage system whose internal structure is discovered during development.
3.2.1 Example: UIMA/Watson
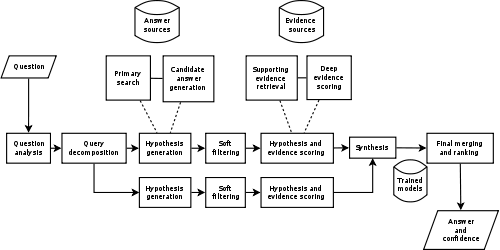
- A derivative is the Unstructured Information Management Architecture, used in the IBM Watson project, which combines a pipeline of modules with an unstructured blackboard.
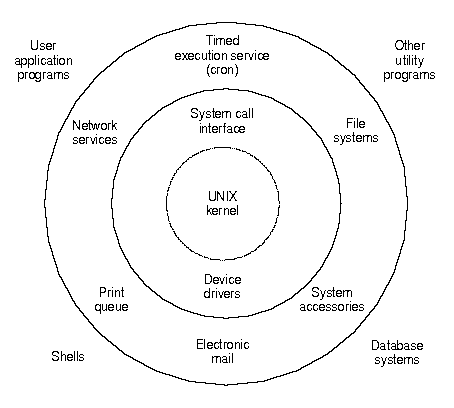
3.3 Layered Abstract Machines
dimensions: modularity
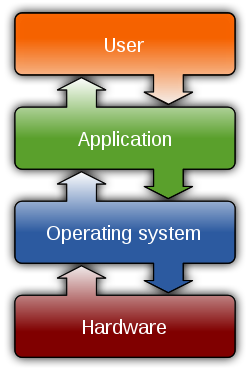
- Functionality divided into layers
- Each layer calls upon services provided only by the layer beneath and provides services to the layer above
3.3.1 Example: Every Operating System Textbook Ever Written
3.4 N-Tier Architectures
dimensions: modularity, deployment
Similar to Layered Abstract Machines, but
-
each layer is independent of the others.
-
e.g., a client-server system is a 2-tier architecture
3.5 Distributed Peer-to-Peer
dimensions: deployment, interface
A general graph of independent processes joined by a common protocol for communication.
3.6 MVC
Model-View-Controller
dimensions: modularity, interface
An approach to organizing programs featuring a GUI
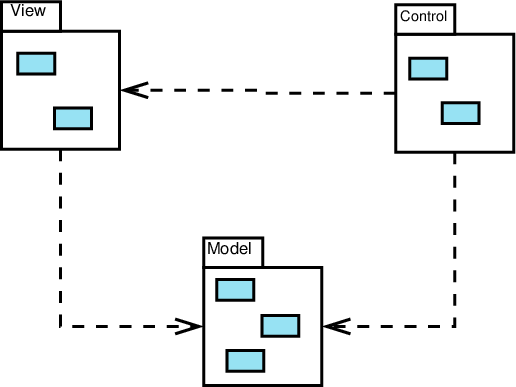
- Separate the system into 3 subsystems
- Model: the “real” data managed by the program
- View: portrayal of the model
- updated as the data changes
- Controller: input & interaction handlers
3.6.1 MVC Interactions
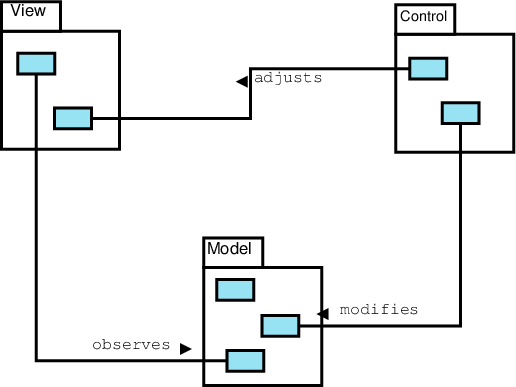
- The Model has no dependencies upon the View or Controller and cannot initiate interactions with either.
- The View can examine the Model – necessary in order to render a visible presentation of the model state
- The View has no dependencies upon the Controller and cannot initiate interactions with it.
- The Controller can examine and alter the Model (e.g., permitting data entry) and the View (e.g., scrolling, paging, zooming)
This pattern has many advantages.
- GUI code is hard to test. Keeping the core data independent of the GUI means we can test it using unit or similar “easy” techniques.
- We can also change the GUI entirely without altering the core classes.
- Separating the control code means that we can test the view by driving it from a custom Control that simply issues a pre-scripted set of calls on the view and model classes
3.7 Micro-Services
dimensions: deployment, interface
“A suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API.” (Martin Fowler)
-
Idea is to keep each service relatively small and specialized. “Do one thing and do it well” (Krause)
-
Because each service is an independent program, may internally employ other architectural patterns.