Myhill-Nerode Theorem
The non-regularity test for languages by Myhill-Nerode is based on the following
theorem
which is in the contrapositive form of the theorem used for nonregularity test. Also it
is a corollary to Myhill-Nerode theorem:
Let 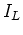 be the followijg relation on
be the followijg relation on 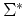 :
For strings
:
For strings  and
and 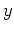 of ,
of , 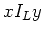 if and only if
{
if and only if
{
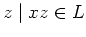 } = {
} = {
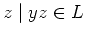 }, that is,
}, that is,
if and only if
they are indistinguishable with respect to 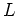 . Then the theorem is is staed as follows:
. Then the theorem is is staed as follows:
Theorem:
A language L over alphabet 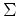 is regular if and only if the set of
equivalence classes of is finite.
is regular if and only if the set of
equivalence classes of is finite.
Proof of Theorem
Necessity
Suppose that a language L is regular and two strings, say x and y, are distinguishable
with respect to L. Then there is a string z such that xz is in L and yz is not in L
(or xz is not in L and yz is in L). This means that if x and y are read by an DFA
that recognizes L, the DFA reaches different states. If there are three strings
that are distinguished with respect to L, then the DFA reaches three different states
after reading those three strings....
Hence if there are infinitely many strings to be distinguished with respect to L,
then the DFA must have infinitely many states, which it can not because a DFA must
have a finite number of states.
Hence if there is an infinite set of strings which are pairwise distinguishable
with respect to a language, then the language is not regular.
Sufficiency
Conversely, if the number of classes of strings that are pairwise indistinguishable
with respect to a language L is finite, then the language L is regular.
To prove this, let [x] denote a class of strings that are indistinguishable
from a string x with respect to L. Note that "indistinguishable with respect to L"
is an equivalence relation over the set of strings (denote it by )
and [x]'s are equivalence classes.
We will show that a DFA that accepts L can be constructed using these equivalence
classes.
Let 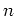 be the number of distinct equivalence classes (i.e. the index) of
and let
be the number of distinct equivalence classes (i.e. the index) of
and let 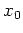 ,
, 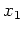 , ...,
, ..., 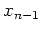 be representatives of those distinct
equivalence classes.
Then we construct a DFA (
be representatives of those distinct
equivalence classes.
Then we construct a DFA (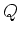 , ,
, , 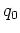 ,
, 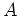 ,
, 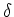 ) as follows:
) as follows:
= {[], [], ..., []}
= [], where [] = [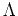 ].
].
= {[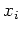 ]
] 
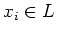 }
}
(![$[x_{i}], a)$](img22.png) = [
= [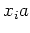 ] for all
] for all 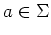 .
.
Let us now show that this machine is in fact a DFA and it accepts the language .
First, note that for every string in [], 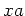 is in exactly one
equivalence class, namely []. For, if and
is in exactly one
equivalence class, namely []. For, if and 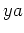 are in different
classes for
are in different
classes for 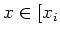 ] and
] and 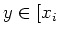 ], then and are distinguishable
with respect to L, making them belong to different []'s.
Hence is a function.
], then and are distinguishable
with respect to L, making them belong to different []'s.
Hence is a function.
Next, let us show that this DFA accepts .
For that, first note that if , then every string in []
is also in L.
We then show that for every string 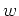 ,
,
![$\delta^{*}([x_{0}], w)$](img30.png) = [
= [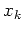 ],
where
],
where 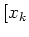 ] is the equivalence class that belongs to. Our proof is
by structural induction on string .
] is the equivalence class that belongs to. Our proof is
by structural induction on string .
Basis Step: 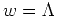 .
.
![$\delta^{*}([x_{0}], \Lambda)$](img34.png) =
=
![$\delta([x_{0}], \Lambda)$](img35.png) by the definition
of
by the definition
of 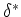 for DFA. Then by the definition of ,
= []. Hence
=
for DFA. Then by the definition of ,
= []. Hence
= ![$[x_{0}]$](img37.png) .
.
Inductive Step: Assume
![$\delta^{*}([x_{0}], x)$](img38.png) = [], where
= [], where
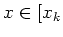 ].
].
Then for every ,
![$\delta^{*}([x_{0}], xa)$](img40.png) =
=
![$\delta (\delta^{*}([x_{0}], x), a)$](img41.png) by the definition of .
by the definition of .
But
= [] by the induction hypothesis.
Hence
=
![$\delta ([x_{k}], a)$](img42.png) = [
= [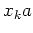 ].
].
Hence
= [].
Hence we have shown that for every string in ,
= [], where 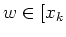 ].
Since
].
Since ![$[x_{k}] \in A$](img45.png) if a string in [] is in , this means
that the DFA accepts .
if a string in [] is in , this means
that the DFA accepts .
Myhill-Nerode Theorem
Let us here state Myhill-Nerode Theorem. First some terminology.
An equivalence relation 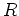 on is said to be right invariant if for every
,
on is said to be right invariant if for every
,
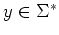 , if
, if 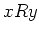 then for every
then for every
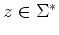 ,
, 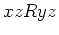 .
.
Also an equivalence relation is said to be of finite index, if the set of its
equivalence classes is finite.
With these terminology, Myhill-Nerode Theorem can now be stated as follows:
The following three statements are equivalent:
(1) A language is regular.
(2) L is the union of some of the equivalence classes of a right invariant
equivalent relation of finite index.
(3) is of finite index.
Proofs are omitted.