

Translating Java Code
Steven Zeil
Programming languages are generally translated in one of two ways:
-
Compilation: source code is compiled to create an executable in “native” machine code, which can then be executed
-
Examples: FORTRAN, C, C++
-
-
Interpretation: execute source code “directly”, translating “on the fly”
-
Examples: LISP, Basic, Perl, shells
-
1 Compiled Program Structure

Here is a rather typical structure for a compiled language (in this case, C++).
-
Source code is compiled into object code (native machine code with some addresses in symbolic form)
-
object code files are linked to form executable (replacing symbolic addresses with real ones)
-
Machine code can then be executed, reading input data and producing output data
2 Interpreted Program Structure
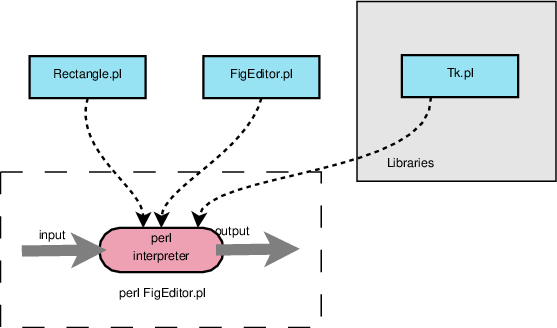
In a purely interpreted language (e.g., Python, Perl, LISP, early forms of Basic, command shells), there is no object code or executable in the native machine code. Instead, an interpreter decides what each statement of source code “means” and executes it immediately.
Pure interpretation can be convenient in terms of turn-around. If you want to make a quick change to a program, you can immediately execute it without needing to wait for it to compile.
On the other hand, pure interpretation can be agonizingly slow. If, for example, you have a statement inside a loop that repeats 10,000 times, not only is that statement performed 10,000 times but it also must be translated 10,000 times. Purely interpreted programs tend to execute much, much more slowly than their compiled counterparts.
3 Translating Java
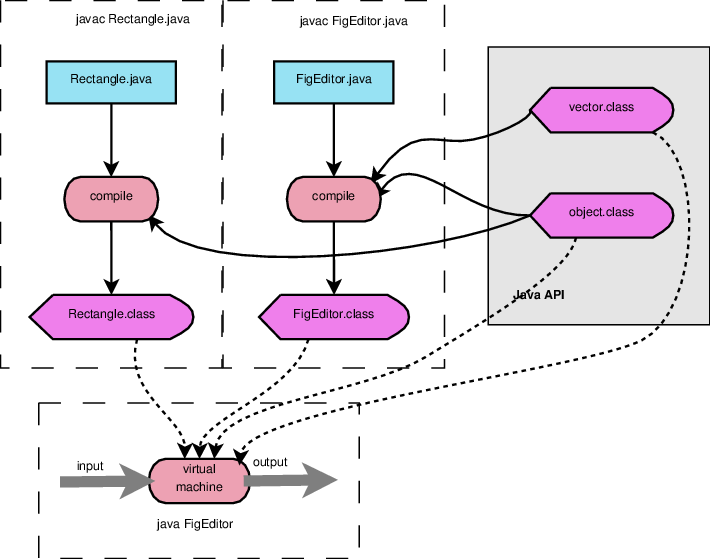
It’s common for people to refer to Java as an interpreted language, but Java actually uses a “hybrid” translation model:
-
Source code in
.javafiles is compiled into object code for an imaginary CPU, the Java Virtual Machine (JVM)-
Stored in
.classfiles
-
-
A simulator for that imaginary CPU is used to interpret the
.classcode-
Unlike “true” compiled code, Java
.classfiles can be run on any CPU to which the simulator has been ported.
-
This hybrid approach allows Java code to be run on any machine that has a JVM program, regardless of what machine was used to compile the code. At the same time, the time penalty of interpretation is greatly reduced because the JVM, although it is technically an interpreter, is interpreting a very simple, low-level language and is therefore adds relatively low overhead.
In recent years, a lot of effort has been put into reducing that overhead further by allowing the JVM to request “just in time” compilation of code so that portions of the program may be rendered into native code.
4 Related Program and File Structures
One thing that will strike C++ programmers as odd is the link between program structure and file structure in Java. Both the JVM and the Java compiler enforce a general rule that file structure must mirror program structure.
In C++, we choose file names related to the names of the classes that they contain. If I had a class Rectangle, I would probably store it in rectangle.h and rectangle.cpp. (Some programmers would capitalize the file names to increase the similarity to the class name.)
Keeping the file names related to the contents is a matter of courtesy in C++ — courtesy to other programmers who might later read your code and to yourself in those cases where you might return to your code some months later wanting to find a portion to re-use in a separate project. It’s not a requirement of C++. If you really wanted to, you could store the class Rectangle in circle.h and guessWho.cpp and no C++ compiler would complain at all about it.
Java is different. Class Foo must be stored in file Foo.java (and the capitalization must match). In part, that’s because Java does not use #include statements to stitch code together, but instead uses the relation between class names and file names to “automatically” locate the files containing source code and compiled code for classes that you mention in your programs.
When you compile your Java source code, the .class files that you produce will carry the same names. So, in Java, a class Foo will have its source code in Foo.java and its compiled code in Foo.class.
Later we will see that classes in Java are typically grouped into packages. Now, if your classes are represented by identically named files, and you group those classes into a package, then you might guess that the files will need to be grouped together as well. And how do we group files? Into directories (folders)!
So Java extends the principle that file structure mirrors program structure by requiring each package to be represented by a an identically named directory. So if Java classes Foo and Bar are part of a package named Baz, then I would expect to find their source code in Baz/Foo.java and Baz/Bar.java and their compiled code in Baz/Foo.class and Baz/Bar.class.
Packages can contain other packages, and it’s also conventional in Java for packages to reflect the URL of the person or organization that wrote the code. Thus, for example, I happen to be the author of a class named Animation that is contained in package AlgAE that is contained in package zeil that is contained in package cs that is contained in package odu that is contained in package edu. The full name of the class is actually edu.odu.cs.zeil.AlgAE.Animation, and I would find its source code in edu/odu/cs/zeil/AlgAE/Animation.java.
It’s a common convention in the Java programming community that the first several levels of a package are simply the reversed for of the the URL where you might go to find that code (or, at least, the people or organization who wrote it. For example, you might expect that anything I write would be stored at http://…cs.odu.edu/…, so my package list starts with edu.odu.cs. In theory, the edu package would contain all code written by members of educational institutions around the world, the package edu.odu would contain all code written at ODU, and the package edu.odu.cs would contain all code written by members of the ODU CS Dept.