


SOLID Design
Steven Zeil
Abstract:
SOLID is an acronym for a collection of principles considered to contribute to effective Object-Oriented Design. Some of these principles we have already seen, possibly under different names. Others are new.
This lesson reviews the SOLID principles and puts them into the context of what we have already seen.
In OOA our emphasis has been to find classes that were natural and intuitive in the application domain. As we move forward from OOA into OOD, compromises to that early vision may be required to obtain a set of classes that
- actually work,
- can be implemented easily, and
- can be maintained easily.
1 SOLID
SOLID is an acronym for a collection of principles considered to contribute to effective Object-Oriented Design:
- Single Responsibility
- Open-Closed Principle
- Liskov Substitution
- Interface Segregation
- Dependency Inversion
The overall theme of SOLID is to control the ways in which different classes depend on each other. SOLID design tries to find class interfaces that are robust even in the face of change.
The SOLID principles are a bit higher-level than the checklists we looked at earlier for C++ and Java. With those earlier checklists, we would expect that two equally experienced programmers would probably apply the checklist rules in nearly identical ways. The SOLID principles are more nuanced. They often require some careful thought about what kinds of changes the software may be subject to in the near future, and two equally experienced programmers may sometimes disagree on that and therefore apply the SOLID principles in different ways.
2 Background: Pre-OO Criteria for Modularity
Much of the discussion and motivation of SOLID harks back to some basic ideas of what constitutes a good “module” or division of a program into modules, from before the time when classes were the primary unit of modularity, when few programming languages had any built-in concept of a module fo gathering and organizing groups of related functions.
2.1 Information Hiding
Formulated by Parnas in 1972, information hiding expresses the idea that
-
every design can be considered as a series of design decisions, and
-
every module should be designed to hide (or, perhaps, isolate) one design decision from the rest of the system.
It’s a common mistake to think of information hiding as programmers hiding implementation details from one another, but it’s really not about that at all. It’s really about isolating the effects of a design decision. Design decisions sometimes need to be changed, either because they were made incorrectly or because the program needs to evolve to meet changing requirements from the real world. If a decision has been properly isolated, then only the module responsible for hiding this decision should need to be rewritten.
Parnas advocated listing the “design decisions most likely to change” for a program, prior to dividing it into modules.
Later, as programming languages evolved, it’s easy to see how encapsulation mechanisms (e.g., the ability to make some members as private) helps to support lets us hide some design decisions, such as the choice of data structure for an ADT.
But encapsulation alone is not the only way that we achieve information hiding. One of Parnas’ early examples involved a requirement for a report to be written to a printer. Parnas suggested that the choice of output device was one of the decisions likely to change. We could hide that decision by burying it inside a private member:
class Whatever {
public:
⋮
void printReport() const;
private:
ostream& outputDevice = getPrinter("mainOffice");
⋮
};
void Whatever::printReport()
{
outputDevice << "Annual Report" << endl;
⋮
}
but Parnas’ solution was more nuanced. He instead suggested that the mechanism for choosing he output device should be hidden distinct from the reporting function(s) that write to it:
class DefaultDevice {
ostream& getDefaultOutput();
};
class Whatever {
public:
⋮
void printReport(ostream&) const;
⋮
};
void Whatever::printReport(ostream& out)
{
out << "Annual Report" << endl;
⋮
}
The higher-level application code can then choose to route the report to the default device. It could also print the report on multiple output devices. And the designation of which output device is the default is entirely separate from the rest of the program.
2.2 Coupling
Coupling is the degree to which modules depend on one another.

Something with high coupling, like this DVR/cable box combo from the late 1990’s, has many dependencies on external entities. By contrast, its modern equivalent might have as few as three external connections (cable-in, HDML out, and digital audio out).
In software terms, we often look at dependencies (in the UML sense). How many other interfaces are used by this module? How many different modules, if changed, could necessitate rewriting or, at least, recompiling, this one?
As a general rule, we want to strive for low coupling. This is often easy to accomplish at the lowest levels of our design (where each module is self-contained and doesn’t need to call on other modules), but trickier as we move up closer to the main application code, which almost by definition is manipulating the maximum amount of diverse data.
The challenge is to hide that diversity. A function to print a publisher’s catalog of books for sale, for example, probably needs to know about (depend on the interface of) a catalog and a book, but, with proper design, might not need to know the details of authors, ISBN and other book metadata. and certainly not the details of what data structure the book uses to store multiple authors.
2.3 Cohesion
Cohesion is the idea that all the members of an ADT should contribute to a common goal. Although the term “cohesion” can sometimes have the connotation of being “sticky”, it also relates to the terms “cohesive” and “coherent”, which we tend to use to describe something that is well-integrated, with few distractions or extraneous elements.
We say that a module exhibits high cohesion if all of its interface elements contribute to an obvious common goal. We say that it has low cohesion if some of the elements seem “tacked on” or superfluous.

In something with high cohesion, all the pieces contribute to a well-defined, common goal.

Each of these tools (considered separately) would be highly cohesive.


  | 1 of 3 |   |
Low cohesion modules can arise because the designer tried to pack too many ideas into a single module, or because its elements were grouped together for weak reasons.
3 Single Responsibility Principle (SRP)
The Single Responsibility principle (Robert Martin, 2003) is a refinement of the idea of information hiding. It applies information hiding specifically to classes, and reinforces the original idea that our choices stem from our preparation for possible future changes.
> A class should have only a single reason to change.
For example, we might consider some additions to our familiar Book class:
class Book {
public:
⋮
/**
* Write a description of this book, properly formatted
* for the publisher's quarterly catalog.
*/
void writeCatalogDescription (std::ostream&) const;
/**
* Update master record in publisher database with any
* changes made to this book.
*/
void save (PublisherDatabase& db) const;
};
Now, consider some possible changes to be made to the Book:
-
We might need to add new attributes or change the implementing data structures used for the “core” book metadata, such as titles, authors, etc.
-
The publisher might decide to switch the catalogs from a paper format to an online format, so that the output of
writeCatalogDescriptionmight now need to emit HTML tags. -
The publisher might change database formats, or redesign the record structure in the databases.
If we considered all three of these changes to be equally plausible, that imply that neither of these two new functions should be incorporated into the Book class.
If we consider the first change to be unlikely, but the other two to be plausible, we might accept placing one of these two functions into the Book class, but not both. (There are other reasons, unrelated to this principle, arguing against putting writeCatalogDescription here.)
SRP is also related to an older idea you might recall from CS250/333,
4 Open Closed Principle (OCP)
Formulated by Bertram Meyer (1988):
Software entities (classes, modules, functions, etc.) should be open for extension but closed for modification.
What does this mean? Well, “extension” and “modification” are again speaking to the potential for future changes.
This principle challenges us to plan for future changes so that we will rarely have to edit and recompile existing classes, but will instead introduce new classes for this purpose.
The most common mechanism for doing this is the combination of inheritance with the ability to override member functions, supplying the desired new behavior in an overridden function body supplied in a new subclass. Now, doing this effectively requires planning. We have to
-
anticipate, when we design the base class(es) in our inheritance hierarchy, just what kind of new behaviors are likely to be requested in the future , and
-
design, in the base class, an function or group of related functions that can successfully embody the range of likely new behaviors.
Consider, for example, the design of the expressions in our spreadsheet program. We might start off with a list of possible operators like basic arithmetic (+ - * /) and a few functions (e.g., sqrt), but it seems likely that this list will grow rapidly. How do we plan for that?
We look at what is likely to be different from one operator to the next:
- the number of operands
- what the operator does to the values of those operands in order to calculate a result, and
- the way in which the operator is printed when displaying an expression
- the way the operator is recognized when encountered as part of an expression.
Then we isolate those behind various function members:
package edu.odu.cs.espreadsheet.expressions;
import java.io.StringReader;
import edu.odu.cs.espreadsheet.ExpressionParseError;
import edu.odu.cs.espreadsheet.Spreadsheet;
import edu.odu.cs.espreadsheet.values.Value;
/**
* Expressions can be thought of as trees. Each non-leaf node of the tree
* contains an operator, and the children of that node are the subexpressions
* (operands) that the operator operates upon. Constants, cell references,
* and the like form the leaves of the tree.
*
* For example, the expression (a2 + 2) * c26 is equivalent to the tree:
*
* *
* / \
* + c26
* / \
* a2 2
*
* @author zeil
*
*/
public abstract class Expression implements Cloneable
{
/**
* How many operands does this expression node have?
*
* @return # of operands required by this operator
*/
public abstract Value evaluate(Spreadsheet usingSheet);
/**
* Copy this expression (deep copy), altering any cell references
* by the indicated offsets except where the row or column is "fixed"
* by a preceding $. E.g., if e is 2*D4+C$2/$A$1, then
* e.copy(1,2) is 2*E6+D$2/$A$1, e.copy(-1,4) is 2*C8+B$2/$A$1
*
* @param colOffset number of columns to offset this copy
* @param rowOffset number of rows to offset this copy
* @return a copy of this expression, suitable for placing into
* a cell (ColOffSet,rowOffset) away from its current position.
*
*/
public abstract Expression clone (int colOffset, int rowOffset);
/**
* Copy this expression.
*/
@Override
public Expression clone ()
{
return clone(0,0);
}
/**
* Attempt to convert the given string into an expression.
* @param in
* @return
*/
public static Expression parse (String in) throws ExpressionParseError
{
⋮
}
@Override
public String toString ()
{
⋮
}
@Override
public abstract boolean equals (Object obj);
@Override
public abstract int hashCode ();
// The following control how the expression gets printed by
// the default implementation of toString
/**
* If true, print in inline form.
* If false, print as functionName(comma-separated-list).
*
* @return indication of whether to print in inline form.
*
*/
public abstract boolean isInline();
/**
* Parentheses are placed around an expression whenever its precedence
* is lower than the precedence of an operator (expression) applied to it.
* E.g., * has higher precedence than +, so we print 3*(a1+1) but not
* (3*a1)+1
*
* @return precedence of this operator
*/
public abstract int precedence();
/**
* Returns the name of the operator for printing purposes.
* For constants/literals, this is the string version of the constant value.
*
* @return the name of the operator for printing purposes.
*/
public abstract String getOperator();
}
-
arity()isolates the idea of how many operands the operator will have.It’s an abstract function, so any subclass of
Expressionwill have to provide a proper body for this. -
evaluate(...)isolates the idea of actually applying the operator to compute a result. -
isInline(),prededence(), andgetOperator(), together, provide enough information for printing most operators-applied-to-operands. If we ever got some kind of operator that was completely off the wall i nthe way it gets written, it is possible to override the defaulttoString()function instead. -
Although it might appear that the
parse(...)function, allows for extension of the way that operators function in input, that’s a bit of a red herring. Closer inspection shows that this function is marked asstatic, meaning that it is not applied to a specific instance of (a subtype of)Expression, but is a general function of the entire class ofExpressions.In fact, parsing expressions is complicated enough that I am unlikely to write such code by hand, but relying on a parser generator to write that code for me (based upon a grammar for the spreadsheet expression language).
So providing input to new types of operators is not actually handled by extension, but by modification (of the grammar).
Is that a violation of the Open-Closed Principle? Yes, it is. But it helps to highlight the idea that design is often a compromise among sometimes conflicting goals. In this case, I believe that even frequent modifications of the grammar would require far less effort than trying to implement a parsing algorithm that is subclass/extension friendly.
So I tolerate this minor violation.
5 Liskov Substitution Principle (LSP)
Barbara Liskov in 1988 formulated the principle that
Subtypes must be substitutable for their base types.
Now, you might think that, given our definition of subtyping, this is a slam dunk. If we declare ‘B’ to be a subtype of ‘A’, then our programming language will allow us to pass an object of type ‘B’ wherever an object of type ‘A’ is expected.
But this principle is really not about what we can convince our programming language to allow. It’s really about expected behaviors.
-
We often say that inheritance captures an “is a” relationship.
-
But “is a” is vague and subject to many interpretations.
-
A common interpretation is “is a specialized form of”.
5.1 Example: A Bird in the Hand
Consider this inheritance hierarchy:
class Animal;
class Bird: public Animal { ...
class BlueJay: public Bird { ...
Nothing too surprising there, right?
Let’s postulate some members for Birds:
class Bird: public Animal {
Bird();
double altitude() const;
void fly();
// post-condition: altitude() > 0.
⋮
};
class BlueJay: public Bird
{
⋮
And I really want to focus on the expected behavior of fly(), which I have documented with a post-condition. If I tell a bird to fly, it should get off the ground.
5.1.1 Is an Ostrich a-kind-of Bird?
class Ostrich: public Bird
{
Ostrich();
// Inherits
// double altitude() const;
// void fly();
//post-condition: altitude() > 0.
Now, Ostrich can provide its own method for fly(), overriding the default implementation.
void Ostrich::fly()
//post-condition: altitude() > 0.
{
plummet();
}
but it can’t satisfy that post-condition.
- An unpleasant surprise for a program traversing a list of
Birds and telling them each tofly().
5.1.2 Substitutability
The ostrich/bird hierarchy violates the substitutability principle.
- You can view this dilemma as a failure of analysis:
-
Who said all birds could fly?
-
A
FlyingBirdssubclass ofBirdwould clarify the situation.BlueJaycould go into that new subclass, butOstrichwould not.
-
(Anyone want to tackle classifying a platypus?)
Martin’s examples of Squares versus Rectangles and Lines versus LineSegments are particularly instructive examples of how subclasses may be perfectly legal in a language, yet be awkward to work with because they violate expectations.
5.1.3 What Happens If You Get It Wrong?
Violations of the LSP generally result in classes where the behaviors are non-intuitive, have surprises (we’ve mentioned before Booch’s “principle of least surprise” that suggests that surprises in a design are almost always unfortunate), or have strange bits of hackery – obscure code designed to force subclasses to behave as expected or to work around subclasses that are known to not to the expected thing.
6 Dependency-Inversion Principle (DIP)
Robert Martin named this in 1996.
High-level modules should not depend on low-level modules. Both should depend on abstractions.
Abstractions should not depend upon details. Details should depend upon abstractions.
Again, it’s tempting to dismiss this as something that is already enforced by almost any programming language, because it is possible to view “high-level” and “abstract” in terms of how we have already written the code instead of as a property of our underlying abstractions.
Let’s think about this in the context of our Spreadsheet example. A Spreadsheet can contain many different kinds of values. Some contain numbers, others contain strings, others might contain dates, monetary amounts, or still other types of data. Typically there is a special kind of “error value” that is stored in a cell when we have formulas that do something “illegal”, such as dividing a number by zero or adding a number to a string.
There are some things we expect to be able to do to any value, e.g.,
string render(int width)
Value* clone()
For values to be useful in a spreadsheet, we must be able to render them in a cell whose current column is of some finite width. The render function, in general, could be quite elaborate. For example, given a lot of room, we might be able to render a number as 12509998.0. If we sharing the column containing that cell, though, we might need to render it as 12509998. Shrink it some more and we might need to render it as 1.25E06. Shrink a little more, and we might need to say 1.3E06, then 1E06. Shrink the available space small enough, and a spreadsheet will typically render a number as “***”.
There may be other operations required of all values as well, such as clone().
Now, the information we have provided so far is general to all values.
But to actually store a numeric value, we need a data member to hold a number (and a function via which we can retrieve it, though we’ll ignore that for the moment). Similarly, we can expect that, to store a string value, we would need a data member to store the string.
We will assume, therefore, that
-
Numeric values have an attribute
dof typedouble. -
String values have an attribute
sof typestring.
6.1 A pre-OO Approach to Variant behavior
class Value {
public:
enum ValueKind {Numeric, String, Error};
Value (double dv);
Value (string sv);
Value ();
ValueKind kind;
double d;
string s;
string render(int width) const;
}
Now, if we had never heard of inheritance (of if we were programming C, FORTRAN, Pascal, or any of the other pre-OO languages, we might have come up with an ADT something like this. (Actually, there are ways to make this more memory-efficient in those languages using constructs called “unions” or “variant records”, but they would not change the point of this example.)
- Any given value will presumably have something useful stored in
dor ins, but not in both.-
In the case of an error value, it may not have anything useful in either one.
-
kindis a “control” data field.- It does not actually store useful data of its own.
- It’s there to tell us which of the variants of value we have stored in any particular value.
- We’ll use this mainly so that we can branch to code appropriate to that variant.
Multi-Way Branching
Functions that work with this kind of value do the bulk of their work inside multi-way branches. For example, a Spreadsheet may periodically need to display the values in all cells currently visible on the screen:
void Spreadsheet::refreshDisplay() const {
for (Cell c: allVisibleCells())
{
Value* v = c.getValue();
int columnWidth = ...;
string rendered = v->render(columnWidth);
displayValueInCell (c, rendered);
}
}
string Value::render(int width) const {
switch (kind) {
case Numeric: {
string buffer;
ostringstream out (buffer);
out << d;
return buffer.substr(0,width);
}
case String:
return s.substr(0.width);
case Error:
return string("** error **").substr(0.width);
}
}
For example, to write the body for the render function, we would probably do something like this. First, we do a multi-way branch on the kind to get to the appropriate code for a numeric, string, or error value. Then in each branch we use a different technique to render the value as a string, then chop the string to the desired width.
- We can expect to see similar multi-way branches used to implement
clone()or just about every other function we might write for manipulatingValues.
Now, if we want to promote information hiding, we might realize that we are embedding a lot of separate design decisions about rendering of different types of values into that one render function. Let’s isolate those into distinct modules:
string Value::render(int width) const {
switch (kind) {
case Numeric:
return NumericValue::renderNumeric (*this, width);
case String:
return StringValue::renderString (*this, width);
case Error:
return ErrorValue::renderError (width);
}
}
⋮
class NumericValue {
public:
static string renderNumeric (const Value& v, int width)
{
string buffer;
ostringstream out (buffer);
out << v.d;
return buffer.substr(0,width);
}
};
class StringValue {
public:
static string renderString (const Value& v, int width)
{
return v.s.substr(0.width);
}
};
class ErrorValue {
public:
static string renderError (int width)
{
return string("** error **").substr(0.width);
}
};
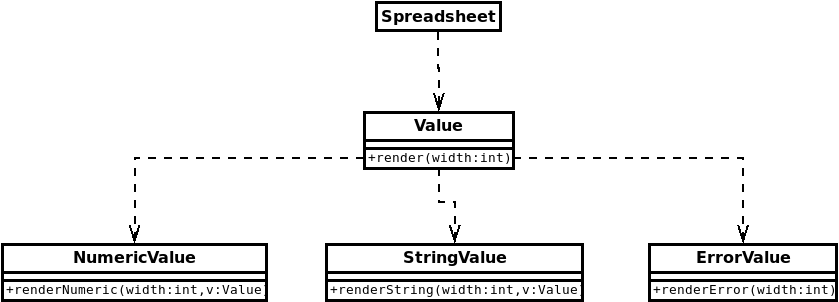
And if we look at the dependencies involved, we see that the Spreadsheet class that requests the rendering in the first place, depends on Value, which in turn depends on each of the specialized value classes.
6.2 Variant Behavior under OO
Now, compare that with the OO approach.
class Value {
public:
virtual string render(int width) const;
};
class NumericValue: public Value {
public:
NumericValue (double dv);
double d;
string render(int width) const;
};
class StringValue: public Value {
public:
StringValue (string sv);
string s;
string render(int width) const;
};
class ErrorValue: public Value {
ErrorValue ();
string render(int width) const;
};
-
We represent each variant with a distinct subclass.
- Only objects of the
NumericValueclass get theddata member. - Only objects of the
StringValueclass get thesdata member. - None of them get the
kinddata member.
- Only objects of the
-
This saves memory when we have large numbers of values floating about (as in a very large spreadsheet).
-
But what’s more important is how it affects the code we write for manipulating
Values.
6.2.1 Variants are Separated
void Spreadsheet::refreshDisplay() const {
for (Cell c: allVisibleCells())
{
Value* v = c.getValue();
int columnWidth = ...;
string rendered = v->render(columnWidth);
displayValueInCell (c, rendered);
}
}
string NumericValue::render(int width) const
{
string buffer;
ostringstream out (buffer);
out << d;
return buffer.substr(0,width);
}
string StringValue::render(int width) const {
return s.substr(0.width);
}
string ErrorValue::render(int width) const {
return string("** error **").substr(0.width);
}
Here’s the OO take on the same render function.
-
None of the details of how to render specific kinds of value have been changed.
-
But we have repackaged that code into subclass-specific bodies.
-
The “variants” are now separate. In a team environment, different people can work on different variants separately.
-
Each subclass operation is simpler.
-
Most important of all, new kinds of values can be added without changing or recompiling the code of the earlier kinds of values.
-
Suppose, for example, that we later decide to add to our spreadsheet the ability to manipulate dates. In the pre-OO style, we would need to look through all our code for any place we had a multi-way branch on the kind, then add a new branch with code to handle a date. Heaven help us if we miss one of those branches! If we’re lucky, our code will crash during testing when we hit that branch with a date value. If we’re unlucky, the crash occurs just as we’re demo’ing the spreadsheet to upper management.
By contrast, to add dates in the OO style, we declare DateValue, a new subclass of Value. We write the code to render date values (which we would have to do in any case) and put it in its own DateValue::render body. Link it with the existing code, and we’re ready to go. None of the existing code had to be touched at all.
6.3 Where’s the Inversion?
Why is this called “dependency inversion”?
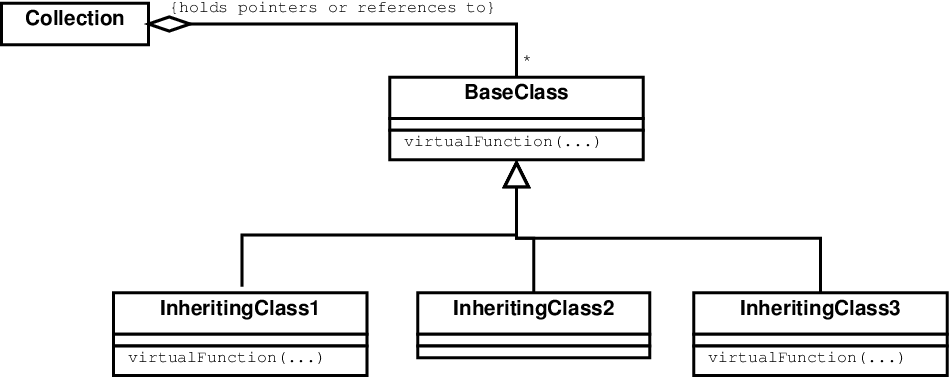
Remember that our pre-OO, multi-way branching approach gave us dependencies that look like this.
The arrows show interface dependencies, but they also illustrate the directions of the calls being made. It sort of makes sense, after all, to think that if you want to call a function in a class, you must “see” and therefore be dependent on that class’s interface.
At least, that makes sense until we start to mask our calls behind dynamic dispatch…
Now, our OO version is simply an instance of our Variant Behavior Pattern in which
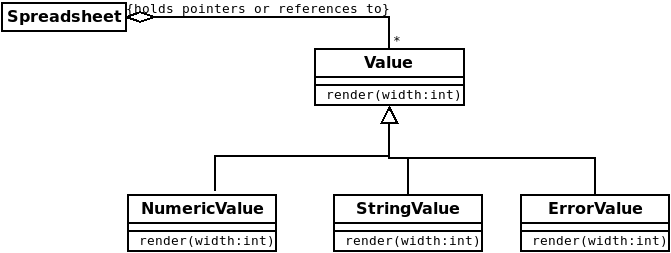
- The
Spreadsheethas a collection of pointers/references toCells, each of which has aValue. - The base class
Valuedefines the virtual functionrender. - Each of the subclasses of
Valueoverridesrenderto provide a single variant behavior.
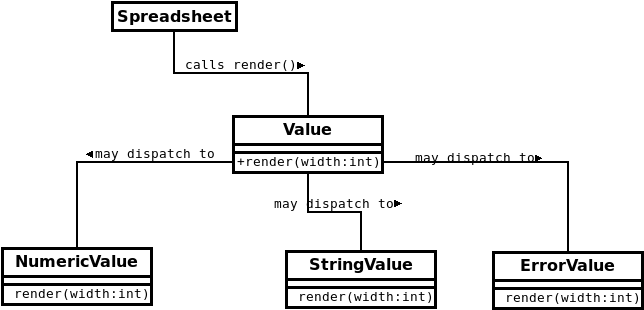
When this code is actually being run, the calls follow pretty much the same pattern as before, though the dynamic binding mechanism is pretty much in play.
- The
SpreadsheetcallsValue::render(...). - That call is resolved by dynamic dispatch so that it actually goes to the
renderfunction body in one of the subclasses.
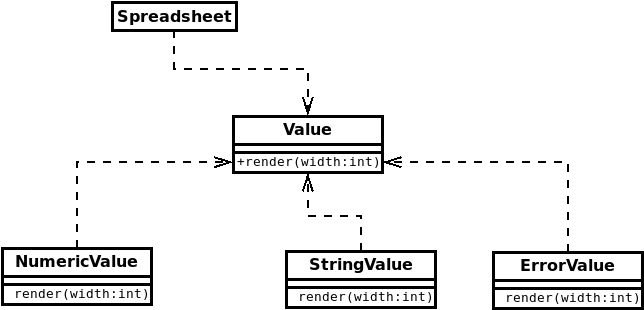
But now look at the dependencies.
-
The
Spreadsheetclass calls a function from theValueinterface, so we have a dependency there.-
It does not know about the three subclasses of
Value. It doesn’t even know that there are three of them. Three or three hundred – makes no difference to theSpreadsheet. -
So there’s no dependency from
Spreadsheetto any of the subclasses ofValue.
-
-
Dynamic dispatch takes care of routing the
rendercalls to the appropriate subclass. TheValuebase class does not know how many subclasses it has. There’s no dependency fromValueto its subclasses. -
Now, the subclasses do know the interface of
Value. When we declare them as inheriting fromValue, that’s a dependency from them toValue. And when they override therenderfunction, they do so in reference to the originalrenderdeclaration in the base class.So each subclass of
Valuedepends on that base class.
Finally, compare the dependency arrows in the last diagram to the ones in the pre-OO code. You can see that the direction of the dependencies between Value and the specialized forms of value have been reversed or inverted.
Compare the the dependency arrows in the last diagram to the directions of the calls in the diagram just before that. Again, those dependencies point in the direction opposite to the direction of the (dispatched) calls.
7 Interface Segregation Principle (ISP)
Robert Martin (2000):
Many client-specific interfaces are better than one general-purpose interface.
When we first learn about inheritance, we tend to focus on situations where we have a single parent class. Over time, base classes tend to acquire more and more public members, and they may wind up becoming quite unwieldy.
We have learned that we aren’t necessarily limited to inheriting from a single base. C++ allows multiple inheritance. Java only allows us to inherit from one base class, but we can also implement (be subclasses of) any number of interfaces.
Why would we bother?
If we are willing to be more flexible and define our classes’ behaviors in smaller (but still cohesive) pieces, we wind up with a vocabulary of simple interfaces to learn and use. More separate pieces, but they can be easier to learn and remember both as individuals and as groups.
7.1 A Negative Example: std Containers in C++
The C++ std library provides a variety of “container” data structures including: vectors, lists, deques, sets, and maps. In CS361, I try to tell students that there are a lot of common patterns to look for in these:
- You can
insertanderaseelements in all of them. - You can request the
size()of all of them and ask if they areempty(). - You can add to the end of a vector, list, or deque using
push_back. - You can add to the end of a list or deque using
push_front. - All of them provide iterators and can be used in range-based for loops.
- Each of them provides a default constructor and a constructor that accepts a range of input values expressed as a pair of iterators.
And that’s all very well and good, but it still falls on the programmer to remember which of these common operations apply to all the containers and which ones apply only to some of the containers.
7.2 A Positive Example: Standard Containers in Java
By way of contrast, let’s look at the opening lines of the Java interface for LinkedList:
public class LinkedList<E> extends AbstractSequentialList<E>
implements Serializable, Cloneable,
Deque<E>, Queue<E> {
So this class has a single base class, declared as
public class AbstractSequentialList<E> extends AbstractList<E> {
which in turn inherits from
public class AbstractList<E> extends AbstractCollection<E>
implements List<E> {
which in turn inherits from
public class AbstractCollection<E>
implements Iterable<E>, Collection<E>
{
Now let’s look at all of the little bits that are being inherited or subclassed. I’m going to hit the highlights here, so this is a simplified treatment that skips some less critical functions.
-
Iterable<E>means that it provides an iterator, obtained by calling the functioniterator().By implication, we can use this in range-based for-each loops.
-
Collection<E>means that we can add elements withadd(...),clear()the container, check to see if it contains an element withcontains, ask if itisEmpty()or what itssize()is, andremove(...)elements. -
An
AbstractCollectionis pretty much just a name for anything that is bothIterableand aCollection. -
List<E>means that we canget(int)a position from an nteger numbered position or ask for the integer positionindexOf(...)an element. We can alssetdata an an integer position.The
Listinterface extendsIterableandCollection:public interface List<E> extends Collection<E>, Iterable<E> {so a “list” is pretty much a “collection” that you can use integer indexing on.
-
An
AbstractListis just a class version ofList. Function bodies are supplied to implement the iterator in terms of thegetand other operations, so newAbstractListsubclasses can be created with less programming effort. -
An
AbstractSequentialListis anAbstractListto which a private “sequential” (array-like) block of memory has been added. So now we are starting to see actual data structures come into play. -
Serializableprovides operations for reading and writing data to a file or over a network pipe. -
Cloneablemeans that theclone()function can be used to make a copy. -
Deque<E>adds functions likeaddFirstandaddLast,getFirstandgetLast, etc., all of which are not absolutely necessary given theaddandgetfunctions, but which in some algorithms may be more descriptive.
So, what does all of this tell us?
-
Let’s be honest. It’s no easier to understand a Java
LinkedListthan a C++std::listif you are coming to them for the first time. -
But that vocabulary of interfaces is actually quite useful because they describe common practices in the Java world that we can use in our own code and announce to anyone reading our code that we have used.
I use
Iterable,Cloneable, andSerializablea lot in my own class designs. They describe things that I often want my classes to do, describe them in a way that is easily understandable, and help me to make sure that I am designing my interfaces in a “Java style”. -
One of the important results of applying ISP is potential reduction in coupling. For example, if I am writing a class with a function that needs to loop through a collection of
Books, I don’t necessarily need to depend on the specific collection type. For example, I can write:class BestSellerList { ⋮ public void processAListOfBooks (Iterable<Book> bookList) { for (Book b: bookList) { doSomethingTo(b); } } ⋮ }and I can pass this function an
ArrayList<Book>, aLinkedList<Book>, or any classes of my own design that implementIterable<Book>:class PublishersCatalog implements Iterable<Book> { public void add (Book b) { ... } public Iterator<Book> iterator() { ... } ⋮ } class BookShelf implements Iterable<Book> { public void add (int position, Book b) { ... } public Iterator<Book> iterator() { ... } ⋮ }which means that
BestSellerListmight not need to depend onPublishersCatalogorBookShelf, even if we intend to use it with objects from those two classes.