

 |
|
|
Abstract
Each development organization has its own working process that it evolves for how it gets software development done. In this lesson, we look at the constituent steps that make up typical instances of these processes, and will survey some of the more common arrangments of those steps into a software development process model:
Abstract
Each development organization has its own working process that it evolves for how it gets software development done.
Although that might sound chaotic, in practice there is pretty broad consensus on what the constituent steps are that make up the entire process. So it becomes a matter of arranging those steps, of tweaking the details, and especially of settling on the relative emphasis and level of detail in these steps.
The arrangements that companies arrive at are seldom entirely innovative. Instead, they fall into a few standard patterns, which we will survey in this lesson.
A software development process model (SDPM), a.k.a., a software life-cycle model, is the process by which an organization develops software.
Although there are many models (in theory, one per development team), there is pretty broad agreement on what needs to go on during this process:
Different SDPMs will divide these activities among phases in different ways.
Let’s talk about a few of these in more detail.
Examine existing system.
Propose a new system
“System” here is used in its generic sense: a collection of people, organizations, machines, and procedures for getting things done. There’s almost always an existing system, even if it is totally un-automated.
If you are a follower of Object-Oriented (OO) approaches, you have a deep conviction that studying and, ultimately, simulating an existing system is a fundamental principle of software development. OO developers never ask the question “Is it possible to build a system that does X?”. That’s because the existing system serves as an existence proof — they’re already doing X, so we start by understanding and then simulating what they are doing now.
We’ll look at requirements in more detail in a later section.
“Design” means deriving
a solution which satisfies the software requirements.
Commonly recognized subproblems include
architectural design,
Examples of architectural design decisions would be
high-level design,
low-level design
A possible breakdown of design activities
You are probably pretty familiar already with procedures for doing high-level and low-level design. Architectural design, on the other hand, is something that is seldom worth worrying about in the scale of projects addressed within an academic semester.
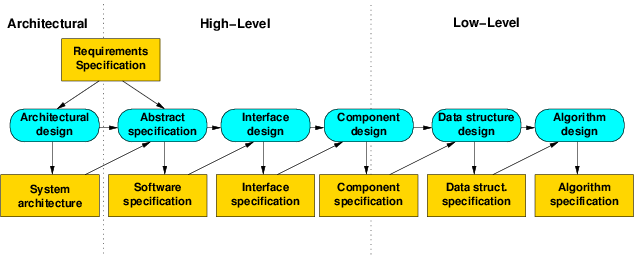
The breakdown shown in this picture is probably more elaborate than you would have attempted, though the component ideas should, considered separately, be clear enough.
The diagram here suggests a fairly document-heavy process typical of Waterfall, our first process model.
Maintenance is another practice that seldom arises in academic projects. Normally, when you do an assignment for a course, you’re completely done with at the end of the semester. Keeping it working, adding new functionality, etc., is not a concern.
But you’ve certainly seen how operating systems, application programs, games, and many other software products are subject to an ongoing process of bug fixes, enhancements, and new releases.
Maintenence can have a number of forms:
fixing problems
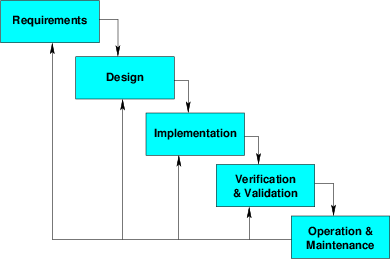
The best known process model
Defining characteristic: movement from phase to phase is always forward (downhill), irreversible
The waterfall model gets its name from the fact that the first diagrams of this process illustrated it as a series of terraces over which a stream flowed, cascading down from one level to another. The point of this portrayal was that water always flows downhill — it can’t reverse itself. Similarly, the defining characteristic of the waterfall model is the irreversible forward progress from phase to phase.
Waterfall is often criticized as inflexible, in large part because of that irreversible forward motion. Many organizations, in practice, will do a kind of “waterfall with appeals”, allowing developers to revisit and revise decisions and documents from earlier phases after jumping through a number of deliberately restrictive hoops.
Most of the activities in Waterfall are familiar, with the possible exception of requirements analysis, which we will be looking at in more detail in a later lesson.
For now, I want to look at Verification and Validation (V&V).
Verification & Validation: assuring that a software system meets the users’ needs.
The principle objectives are:
Verification:
Validation:
Verification is essentially looking for mistakes in our most recent bit of work by comparing what we have now to the most recent “official” document defining our system.
Validation is a return to first principles, comparing what we have now to what we (or our customers) originally wanted.
You might think that, in a process divided into steps, if we do each step “correctly”, then the entire sequence must be “correct”. In practice, though, the accumulation of small errors can lead to massive alterations over time. (That’s not just a matter for programmers.)
Most V&V activities mix verification and validation together to different degrees.
Testing
Industry figures of 1-3 faults per 100 statements are quite common.
Is testing verification or validation? A great deal depends on how we decide whether the test output is correct. If we do this by viewing the data ourselves and looking for things that jump out to our eyes as “wrong”, then we are doing mainly validation. On the other hand, if part of our design process was to set up a set of tests with files of their expected outputs, and we are simply comparing the actual output files to the expected output files, then we are doing more verification.
usually conducted by the programmer.
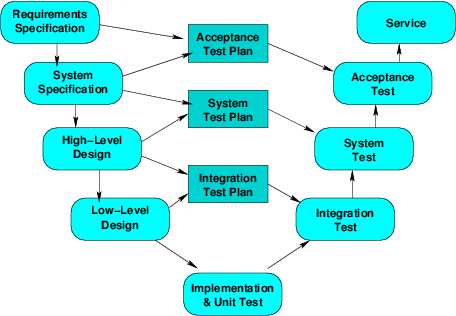
Although the waterfall model shows V&V as a separate phase near the end, we know that some forms of V&V occur much earlier.
So this phase of the waterfall model really describes system and acceptance testing.
A Still-broader View
Even the “V&V V” does not capture the full context of V&V:
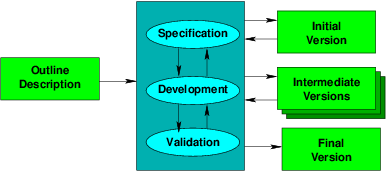
As a counter-reaction to what many believe to be an overly rigid waterfall model, there are a variety of incremental approaches that emphasize quick cycles of development, usually with earlier and more user-oriented validation.
There is a greater emphasis on producing intermediate versions, each adding a small amount of additional functionality. Some of these are releases, either external (released outside the team) or internal (seen only by the team), which may have been planned earlier.
What’s the difference between iterative and incremental?
“Iterative” means that we can re-visit decisions, design, and code produced in earlier iterative steps.
“Incremental” means that each iteration produces just a small unit of additional functional behavior. We don’t try to build major subsystems of the project in a single pass.
This often requires a more “vertical” view in which we implement a bit of high level control code and pieces of related low-level code.
As opposed to the “horizontal” approach of working “bottom up” and implementing the low-level ADTS, then the code that calls, upon them, then …, ending with the top-level interface ot the whole program.
Or the “horizontal” approach of working “top down” and implementing the most abstract code (the GUI or command-line interfaces), then functions that they call, then the … ending with the lowest-level ADTS that don’t call on anything else.
Iterative versus Incremental Models
Iterative – we do some set of process steps repeatedly.
To use a programming analogy, this is iterative:
while (!done) {
⋮
}
Incremental – we accumulate value in small steps.
To use a programming analogy, this is incremental:
total += x;
Incremental development is almost always iterative, but you can be iterative without being incremental.
Variations
Some projects employ throw-away prototyping, versions whose code is only used to demonstrate and evaluate possibilities.
Evolutionary prototyping keeps the prototypes, gradually evolving them into the final deliverable
Some waterfall projects may employ incremental schemes for parts of large systems (e.g., the user interface).
Poor process visibility (e.g., are we on schedule?),
Continual small drifts from the main architecture leading to poorly structured systems.
Dead-ends (the local optimization problem)
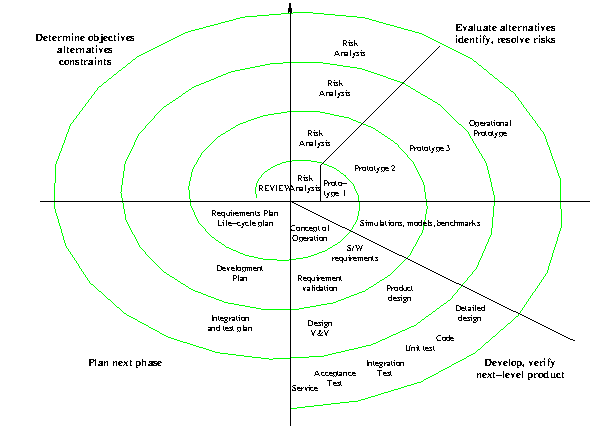
1986, Boehm
An iterative approach with a focus on risk management
Each iteration builds on the earlier ones
risk: an uncertain outcome with a potential for loss
Examples:
Spiral Phases
1997, Jacobsen, Booch, and Rumbaugh,
Best Practices
These three were already some of the biggest names in OOA&D before they decided to collaborate on a unified version of their previously distinctive approaches.
Their collaboration coincided with their being hired by Rational Corp., a major vendor of software development tools. Hence the “Rational” in RUP refers to the name of the company. It’s not bragging. They aren’t saying that this is a uniquely intellectual approach or that Waterfall, Spiral, et. al., are “irrational”.

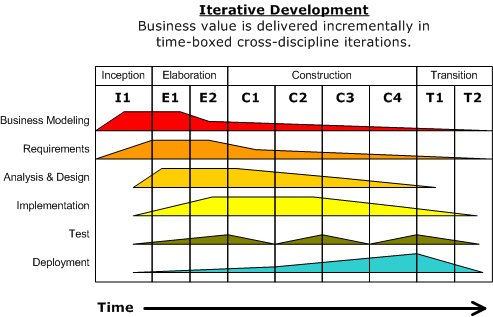
Inception: initial concept
Elaboration: exploring requirements
Construction: building the software
Transition: final packaging
Releases
One task during Elaboration is to plan releases:

Major phases are divided into increments, each of which ends with a release.
A release is some kind of product that implements some part of the required functionality
The release plan records decisions about
The term “increments” gets used a lot in different models. Sometimes it refers, as it does here, to the time period during which the next release of the software is developed. In other cases it refers to the next version of the software. In other cases it refers to the software release itself.
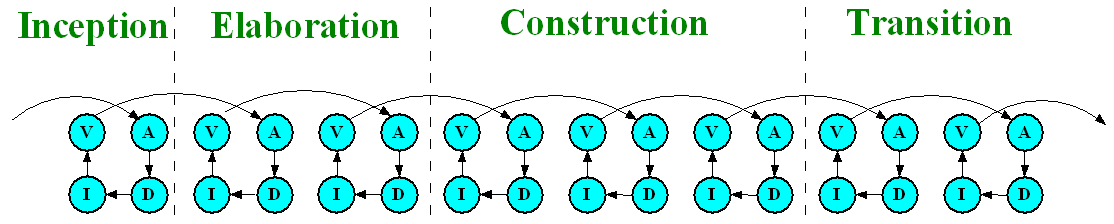
Analysis: what do we need the (currently considered part of the) system to do?
Design: how do we get it to do that?
For example, deep in the implementation phase of a Waterfall project, a programmer is assigned a function to implement.
That programmer will
But we aren’t in the analysis, design, or validation phases.
The diagram on the right is supposed to illustrate that, although the percentage of time devoted to the activities of analysis, design, implementation, and validation, none of those activites ever entirely go away and are, once and for all, done.
A process model may still use some of these same terms as the name for major phases, but that’s really a different sense of the terms. For example, the “Design” phase of the Waterfall is when the language in which we “implement” is the collection of notations and diagrams that we use for system design. But we still analyze, design, implement, and validate our Design decisions.
ADIV
In the RUP, all progress is made as continual ADIV cycles
RUP supports development via a series of models.
The most important of these are
Domain Model
Analysis Model
Design Model
Models Evolved
RUP embraces the
Object-Oriented philosophy
- Every program is a simulation
- The quality of a program’s design is proportional to how faithfully the objects and interactions in the program reflect those in the real world
Domain, analysis, and design models all focus on how classes of objects interact with one another
Most of the classes in the design are presumed to have already been described as part of the analysis model,
A modern variant of incremental development.
Agile development is
Emphasis Areas
Emphasis is on
We’ll look at Agile in more detail later in the semester, after we have learned more about these “best practices” that lie at the heart of the process.
|
|