

 |
|
|
Abstract
User stories are used in incremental SDPMs as a way of organizing work during software construction.
A user story is a simple description of desired functionality, often written as a single sentence on an ordinary index card.
Over time, user stories are modified by
In an incremental construction process, small sets of stories are chosen for an upcoming increment as the target for the next round of construction.
Key idea in all agile variations.
A user story is
They must be validatable.
As a calendar owner, I want to view my schedule for the coming week.
As a visitor, I want to see when a calendar owner has free time in their schedule.
As a calendar owner, I want to receive email notication when someone accepts a proposed appointment.
As a systems administrator, I want to back up all calendars so that the data is safeguarded.
These illustrate some common patterns:
{role}, I want {goal/desire}”{role}, I want {goal/desire} so that {benefit}”…despite the focus on functionality and non-functional characteristics.
Stories should express a customer’s point of view, using the customer’s language.
One way to achieve this is to ask the customers to write the stories.
At some point in the process, we must add estimates to our stories indicating how much time we think it will take to complete them. Such estimates aid us in future scheduling. We want to select, for each upcoming increment, enough stories to add a substantial amount of functionality, but not so many that we will be unable to complete them in the time allotted for that increment.
The estimates are commonly not written in hours, person-days or other real time units, at least not unless your team is actually experienced enough to do a good job at coming up with such numbers. Instead, a groups of “typical effort” stories is selected as defining unit 1.0 difficulty, and the others are expresssed in numbers relative to that, e.g., “I think this will take half again as long as the typical stories, so I will estimate it at 1.5.”
The team must estimate the effort required to implementation a story.
“This story will take half again as much time as our average story.”
Big, complicated stories are harder to estimate
Good stories have completion criteria that can be validated.
It’s important to know when we are done implementing a story.
Agile generally recognizes stories as only 0% or 100% completed – no fractions.
Definition of Done: team’s agreed-upon criteria for declaring work done (e.g., tests passed, integrated, documented, …)
A common saying among agile teams:
“I know that you are done, but are you DONE-done?”
Non-functional stories
Stories can describe new functionality or improvements to existing functionality:
May be harder to define precise completion criteria.
Automate integration build
Improve performance
Implement interfaces between subsystems
The traditional user story is customer-centric.
But sometimes there are units of work required that don’t fit the traditional definition.
Remember that each increment is supposed to yield a runnable program that implements some addition functionality not present in earlier increments.
Stories also add functionality, but an individual story might not yield something visible while running the program.
In planning our next increment or release, we select a set of stories to be implemented during our next development interval.
Together, they should add up to a visible addition of functionality to the working system.
Use the estimates attached to each story to scale the amount of work planned for this development interval to a reasonable size.
Early in a project, we might need to guess just how much time it will take to 1 estimated unit of effort.
This should become clearer as we move forward through the project.
There are a variety of ways to visually organize stories to enhance planning and to give visual evidence of the progress being made.

A term used in conjunction with story-based planning is “backlog”.
In normal English usage, “backlog” sounds negative: You have a backlog because you are “backed up” – your progress has been too slow.
In incremental development, there is no such negative connotation.
The project backlog is a list of unimplemented:
When we pick up a story for development there may be many steps required to actually complete it.
It’s possible that a developer will do some tasks on one story, then move to tasks of a second story, then return to the first, etc.
In the spreadsheet stories, I suggested that the stories for the first increment might be
- As a calculation author I would like to load a spreadsheet via the CLI.
- As a calculation author I would like to generate a value report via the CLI.
- As an API user I would like to create a new spreadsheet.
- As an API user I would like to load a spreadsheet from a file containing only simple assignments.
- As an API user I would like to add a numeric literal to a cell in a spreadsheet.
- As an API user I would like to obtain the value of a cell whose formula contains only literals.
Of these, I would likely pick
- As an API user I would like to create a new spreadsheet.
to start.
Then, I would break it into tasks, some of which would be necessitated by this being the first story developed in a project:
Set up project repository
Set up directories and initial build file.
Design initial spreadsheet API.
Write unit test for spreadsheet creation via that API.
Implement the spreadsheet creation function.
Commit implementation to the repository.
Some comments about these tasks:
The italicized items are all concepts that we will tackle in a subsequent lesson.
The sequence defined by items 3-4-5 is characteristic of Test-Driven Development:

Task boards show the completed and in-progress stories for the current increment:
The “To do” column is sometimes labeled the “sprint backlog”
To me, one of the challenges in designing good stories and in scheduling them is to envision possible increments.
When a large portion of the implementation is done, this is relatively easy.
But what about when you have nothing at all working yet?
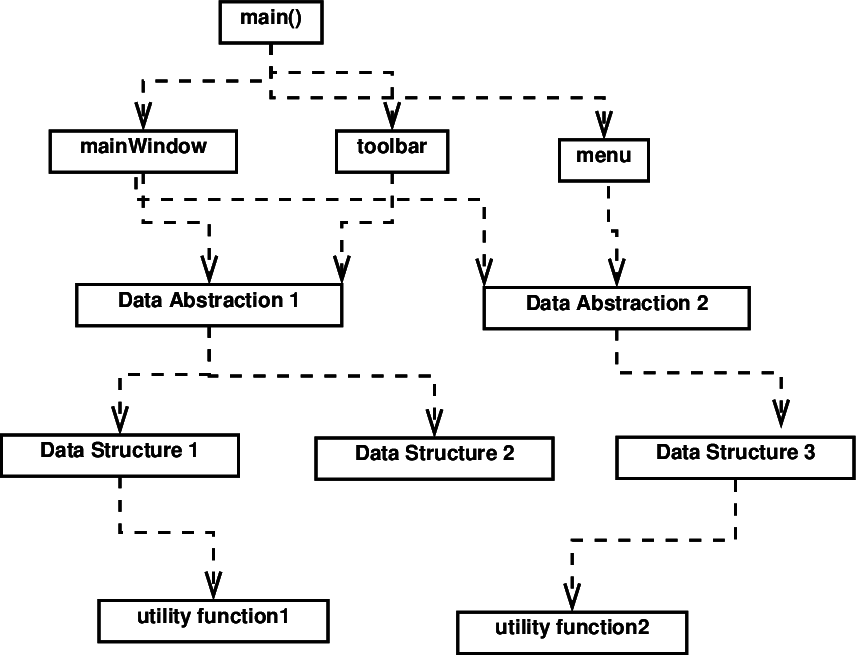 Partly, I think this is awkward because there’s a mis-match between how we design and think about code and how we schedule increments.
Partly, I think this is awkward because there’s a mis-match between how we design and think about code and how we schedule increments.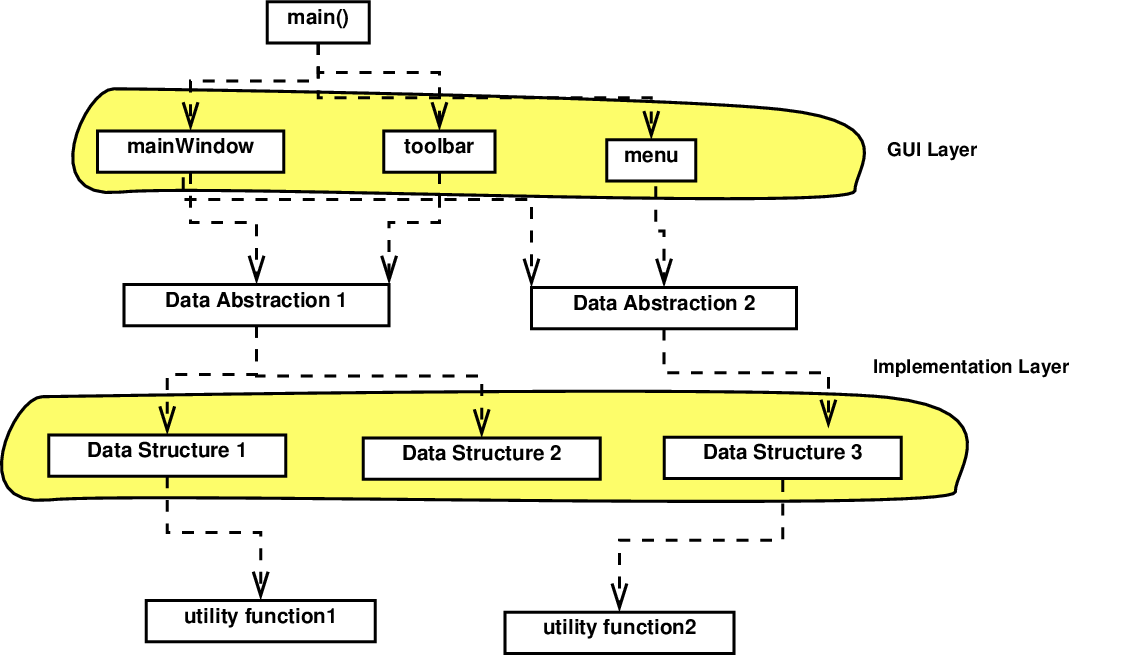
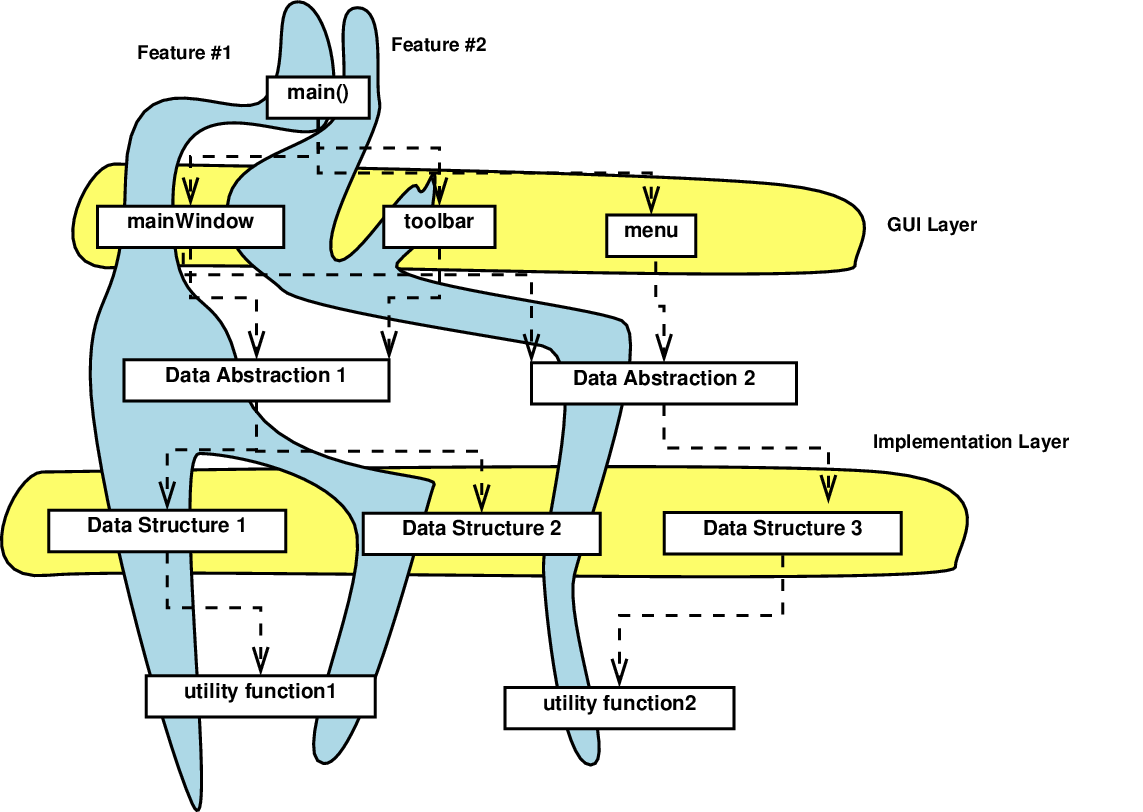
Incremental development is also iterative – we can revisit components in later iterations.
Sometimes that’s easy.
Sometimes it’s not
Think of a typical ADT - how can you implement part of it?
If we need to implement part of a complicated ADT during an increment…
Choose a quick (to implement) data structure now, with the intention of replacing it later when we need more of the ADT API to work.
Or, take a lesson from integration testing
|
|