


Hashing
Steven J. Zeil
Hashing is an important approach to set/map construction.
We’ve seen sets and maps with $O(N)$ and $O(\log N)$ search and insert operations.
Hash tables trade off space for speed, sometimes achieving an average case of $O(1)$ search and insert times.
1 Hashing 101: the Fundamentals
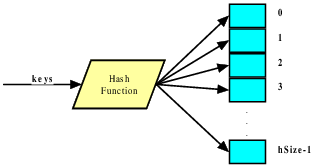
Hash tables use a hashing function to compute an element’s position within the array that holds the table.
If we had a really good hashing function, we could implement set insertion this way:
public class set<K> {
⋮
private final int hSize = ...;
private Object[] table = new Object[hSize];
public void insert (K key) {
int h = hash(key);
table[h] = key;
}
⋮
and searching through the table would not be much harder:
⋮
boolean contains (K key) {
int h = hash(key);
return (table[h].equals(key));
}
⋮
1.1 The Ideal: Perfect Hash Functions
For this overly-simple form of hashing to work, the hash function must
- return values in the range
0…hSize-1 - be fast and easy to compute
- return a unique value for each key.
A function that satisfies these requirements is called a perfect hash function.
Suppose, for example, that we were writing an application to work with calendar dates and wanted to quickly be able to translate the names of days of the work week (excluding the weekend) into numbers indicating how far into the week the day is:
| Key | Value |
|---|---|
Monday |
1 |
Tuesday |
2 |
Wednesday |
3 |
Thursday |
4 |
Friday |
5 |
If we are willing to use a table with a little bit (or a lot) of extra space, we could use a function
int hash(String dayName) {
return dayName[1] - 'a';
}
because each of those seven strings has a distinct second character.
So we can set up the table:
String[] days = {"Monday", "Tuesday",
"Wednesday", "Thursday", "Friday"};
int[] table = new int[96];
for (int i = 0; i < 5; ++i)
table[hash(days[i])] = i+1;
```
and then afterwards, we can look up those day names in $O(1)$ time:
int dayOfWeek (String dayName) {
return table[hash(dayName)];
}
---
Perfect hash functions are usually only possible if we know all the
keys in advance. That rules out their use in most practical
circumstances.
There are some applications where perfect hash functions are
possible. For example, most programming languages have a large number
of reserved words such as "`if`" or "`while`", but for any given
language the set of reserved words is fixed. Programmers who are
writing a compiler for that language may use a perfect hash function
over the language's keywords to quickly recognize when a word read
from the source code file is really a reserved word.
## The Reality: Collisions
For the most part, though, we can't really expect to have perfect
hash functions. This means that some keys will hash to the same table
location.
Two keys <span class="firstterm">collide</span> if they have the same hash function
value.
For example, if we were to expand our days of the week code to include
the weekend, then Sunday and Tuesday would collide under our chosen hash
function because both have the same second letter. We could compensate
with a more complicated hash function, perhaps one involving a pair of letters,
but this could also increase the number of unused/wasted slots in the table.
Collisions are, in most cases, unavoidable, simply because we do not know,
in advance, what all of the keys will be.
Consequently, we say that a
good hash function will
1. return values in the range `0` ... `hSize-1`,
2. be fast and easy to compute, and
3. have a very small probability of producing collisions.
Actually, the first of these three requirements is usually enforced
inside the hash table code by the simple technique of taking `hash()`
modulo `hSize`:
private final int hSize = ...;
private Object[] table = new Object[hSize];
⋮
public void insert (K key) {
int h = hash(key) % hSize;
table[h] = key;
}
boolean contains (K key) {
int h = hash(key) % hSize;
return (table[h].equals(key));
}
So, in practice, we worry about hash functions being
1. be fast and easy to compute, and
2. have a very small probability of producing collisions.
# Hash Functions
Hashing is so common in Java that it is part of the standard interface to
every object:
package java.lang;
public class Object { /*…/ /* * Returns a hash code value for the object. This method is supported for * the benefit of hash tables such as those provided by HashMap. * * The general contract of hashCode is: * * - Whenever it is invoked on the same object more than once during an * execution of a Java application, the hashCode method must consistently * return the same integer, provided no information used in equals * comparisons on the object is modified. This integer need not remain * consistent from one execution of an application to another execution of * the same application. * - If two objects are equal according to the equals method, then calling the * hashCode method on each of the two objects must produce the * same integer result. * - It is not required that if two objects are unequal according to the * equals method, then calling the hashCode method on each of the two objects * must produce distinct integer results. However, the programmer should be * aware that producing distinct integer results for unequal objects may * improve the performance of hash tables. * * @return a hash code value for this object. */ public int hashCode() { … }
/* * Indicates whether some other object is “equal to” this one. * * @param obj the object to be compared against this one * @return true if the object equals the obj argument / public boolean equals(Object obj) { … } /…*/ }
You might compare the above lengthy description of `hashCode` to what we had just been saying about a good hash function:
> A good hash function will
>
> 1. be fast and easy to compute, and
> 2. have a very small probability of producing collisions.
Unless we have special knowledge about the keys, the best we can
say about reducing the probability of collisions is that we hope that
our hashing function will distribute the keys uniformly, i.e., if I am
drawing keys at random, the probability of the next key's going into
any particular position in the hash table should be the same as for
any other position.
---
So the characteristics that we'll look for in a good hash function
* Fast and easy to compute
* Distributes the keys uniformly across the table.
The possibility of collisions also forces us to revise those simple
table retrieval algorithms to include <span class="firstterm">collision handling</span>, which we
will discuss a little later..
## hashCode & equals
Every object in Java has a `hashCode` function. Every object in Java has an `equals` function.
These are closely related.
* In both cases, the default implementation provided by the `java.lang.Object` class is generally not useful. We have to _override_ both functions in our own classes if we want to actually use them.
* And we do want to use them, quite often. That's why both of these functions were highlighted in my [Class Designer's Checklist](doc:java-checklist).
There's another sense in which these two functions are related. Their implementations need to be consistent with one another:
If we have two objects, `x` and `y`, of the same class,
* if `x.equals(y)`, then it must be true that `x.hashCode() == y.hashCode()`.
* if `x.hashCode() != y.hashCode()`, then `x.equals(y)` must be _false_.
* if `!(x.equals(y))`, then it should be likely that `x.hashCode() != y.hashCode()`.
In practice, this generally means that hash codes are computed on the same set of data fields that are used in the `equals()` comparisons. When we first discussed [comparing objects](doc:comparingData), we looked at a class `Book` and suggested that, dpending on our intended application, we could write a plausible `equals()` function that compared nearly all `Book` fields (title, authors, publisher, etc.) or that only compared one (ISBN). Now if we consider the need to keep `hashCode()` consistent with `euqls()`, we would have to say that, if `Book.equals` compares only ISBN, then `Book.hashCode` should compute only on the ISBN. But if if `Book.equals` compares multiple data members, then `Book.hashCode` should work on those same data members.
# Hash Functions: Examples
The proper choice of hash functions depends upon the structure and distribution of the keys.
> Don't get hung up on trying to find hash functions that
> "mean something". Most hash functions don't compute anything
> useful or "natural". They are simply functions chosen to
> satisfy our requirements that they be fast and distribute the keys
> uniformly over the range `0` ... `hSize-1`.
## Hashing Integers
This is the easiest possible case.
If we have a set of integer keys that are already in the range
`0` ... `hSize-1`, we don't need to do anything:
int hash(int i) {return i;}
---
So integer keys are easy, but you can't always take them for
granted. I once worked for a company that assigned an integer ID
number to every employee. When the computerized system for the company
payroll was first instituted, the way the IDs were assigned when like
this:
* Start with a list of all current employees, in alphabetical order by name.
* Assign the first person in the list the ID 00005, the next person 00010, then 00015, and so on.
This left "gaps" in the ID number sequence that could be used in subsequent years for new employees.
When a new person was hired,
someone would compare the new person's name to the alphabetical list
of employee names and would assign the new person a number lying
somewhere in the gap between the people whose names came just before
and after the new person's.
Because of this scheme, more than 3/4 of the ID numbers in the
company were evenly divisible by 5.
Now, suppose we took those numbers and hashed them into a table of
size `hSize==100`.
int hash(int i) {return i % 100;}
There are 20 numbers divisible by 5 in the range from 0 to
99. So 3/4 of the ID numbers would hash into only 1/5 of the table
positions. These numbers are not being distributed uniformly.
There is, as it happens, a very easy fix for this: add one more
element to the table. The same set of IDs will do very well with an
`hSize` of 101:
int hash(int i) {return i % 101;}
Check it out:
| keys | hash to |
|---|---|
| 00005, 00010, ... 00100 | 5, 10, ... , 100
| 00105, 00110, ... 00200 | 4, 9, ... , 99
| 00205, 00210, ... 00300 | 3, 8, ... , 98
| 00305, 00310, ... 00400 | 2, 7, ... , 97
| ` ⋮` | ` ⋮` |
The lesson here: the distribution of the original key values is important.
### The Curious Power of the Prime Modulus
The fact that 101 worked so well for `hSize` is no
accident. The trick of taking the integer key modulo
`hSize`
* preserves uniform distribution if already present in a set of keys, and
* tends to increase the uniformity in a set of keys <span class="emph">if</span> `hSize` is a prime number.
Consequently, it's a standard part of hashing "lore" to try and use
prime numbers for the hash table size. Shortly,
we'll see that, for some collision handling schemes, the use of prime
table sizes is particularly important.
## Hashing Character Strings
Hash functions for strings generally work by adding up some
expression applied to each character in the string (remember that a
`char` is just another integer type).
We need to be a little bit careful to get an appropriate distribution. For one thing, although a `char` could be any of 255 different values, most strings actually contain only the 96 "printable" characters starting at 32 (blank).
In addition, we often want to make sure that similar strings, likely to occur together, don't hash to the same location. For example, many words differ from one another only in having two adjacent characters transposed (and, if we were programming a spelling checker, you might want to consider that character transposition is a very common spelling error). So a simple hash function like this:
int hash (String s) { int h = 0; for (int i = 0; i < s.length(); i++) h += s.charAt(i); return h; }
doesn't work very well. Words that differ only by
transposition of characters would have the same hash value.
A better approach is to use multipliers to make every character
position "count" differently in the final sum.
int hash (String s) { int h = 0; for (int i = 0; i < s.length(); i++) h = C*h + s.charAt(i); return h; }
where `C` is an integer multiplier, usually chosen as a prime
number.
---
Luckily, we would seldome need to write our own hash function for `String`, as the `java.lang.String1` class provides its own working `hashCode()` function, and we can generally trust that.
## Hashing Compound Structures
When you need a hash function for a more elaborate data type, you
generally try to
* figure out which components of the compound type are critical to identifying the object
* then compute hash functions on those components and combine those hash values into an overall hash function.
<cwm tag="splitColumns"/><cwm tag="leftColumn"/>
public class Book { private Author theAuthor; private String theTitle; private String theIsbn; private Publisher thePublisher; private int theEdition; private int theYear;
public Book (Author author, String title, String isbn, Publisher publisher, int editionNumber, int yearPublished); /*…/ public int hashCode() { … }; /…*/ };
<cwm tag="/leftColumn"/><cwm tag="rightColumn"/>
For example, if we wanted a hash table of books, we might
take advantage of the fact that each book has a unique ISBN number:
<cwm tag="/rightColumn"/><cwm tag="/splitColumns"/>
public int hashCode() { return theIsbn.hashCode(); }
so that hashing a book turns into a simple problem of hashing a single string.
But what if we didn't have that nice convenient ISBN field? Then
we would need to use a combination of the other fields that, combined,
would uniquely identify the book:
public int hashCode() { return theAuthor.hashCode() + 73*theTitle.hashCode() + 557*thePublisher.hashCode() + 677*theEdition; }
(Why not `theYear`? Because once we have determined the publisher and
the edition, the year is already fixed, so adding that in as well
won't help distinguish one book from another.) Notice how this hash
function breaks down into a series of hashes on other data types,
including strings and integers.
* Notice, also, the recurring theme of using prime numbers as
multipliers. Prime numbers as multipliers are useful in minimizing
collisions when the hash values of different components come out as
equal values or as simple multiples of one another.
### Objects.hash
The pattern of taking a sum of hash values, weighted by prime multipliers, is a common one. It's common enough that Java provides a useful shortcut. The function `java.utils.Objects.hash(...)` takes a variable number of parameters and generates an overall hash code for that collection using the prime-multiplier sum scheme we have just outlined:
public int hashCode() { return java.util.Objects.hash(theAuthor, theTitle, thePublisher, theEdition); } ```