


Linked List Applications
Steven J. Zeil
Linked lists and related structures form the basis of many data structures, so it’s worth looking at some applications that aren’t implemented via the std::list that we will be examining shortly.
We’ll look at issues that arise in ADT implementation, then in storage management, first in our own code, then at the operating system level.
1 Using Linked Lists in ADTs
We have previously explored implementations of a Book ADT that used various forms of array to store the list of authors. Now let’s consider the possibility of using a linked list.
1.1 The Header
class Book {
public:
typedef const AuthorNode* AuthorPosition;
Book (Author); // for books with single authors
Book (const Author[], int nAuthors); // for books with multiple authors
Book (const Book& b);
~Book();
const Book& operator= (const Book& b);
std::string getTitle() const { return title; }
void setTitle(std::string theTitle) { title = theTitle; }
int getNumberOfAuthors() const { return numAuthors; }
std::string getISBN() const { return isbn; }
void setISBN(std::string id) { isbn = id; }
Publisher getPublisher() const { return publisher; }
void setPublisher(const Publisher& publ) { publisher = publ; }
AuthorPosition find(const Author& au) const;
AuthorPosition next (AuthorPosition pos) const;
AuthorPosition getFirst () const;
void addAuthor (AuthorPosition at, const Author& author);
void removeAuthor (AuthorPosition at);
private:
struct AuthorNode {
Author data;
AuthorNode* next;
AuthorNode (const Author& au, AuthorNode* nxt = 0)
: data(au), next(nxt)
{}
};
std::string title;
int numAuthors;
std::string isbn;
Publisher publisher;
AuthorNode* first;
AuthorNode* last;
void clear();
};
To use a linked list, we need to start by declaring the data type for the linked list nodes. In this case, there’s no reason to ever show this type to code outside of this class, so I have chosen to nest the AuthorNode type within the Book class and to make it private.
We will also need pointers to (at least) the start of the linked list. I have opted for a first/last header instead, so that adding to the end of the list of authors can be implemented efficiently.
We can’t expect to add and retrieve authors by numeric position if we are going to use a linked list, so I have added various position-based functions that manipulating and retrieving authors. This is far from an ideal solution to this problem. Ideally, we should be able to come up with a way of manipulating authors that does not change the public interface of Book just because we change the internal data structure. In a later lesson, we’ll see a more elegant approach to this design when we introduce iterators.
Finally, we note that we definitely have a data structure containing pointers to data that we don’t really want to share. For this reason, we know that we will need to declare the Big 3 and will need to provide an appropriate deep-copy implementation.
1.2 Adding Authors
To add an author at a given position, we consider 4 distinct cases:
void Book::addAuthor (Book::AuthorPosition at, const Author& author)
{
if (first == 0)
// List is empty - adding to both first and last position
first = last = new AuthorNode (author, 0);
else if (at == 0)
{
// Adding to the end of the list
last->next = new AuthorNode (author, 0);
last = last->next;
}
else
{
// Adding somewhere not at the end
AuthorNode* newNode = new AuthorNode(author, (AuthorNode*)at);
if (at == first)
first = newNode;
else
{
AuthorNode* prev = first;
while (prev->next != at)
prev = prev->next;
prev->next = newNode;
}
}
++numAuthors;
}
-
Adding to an empty list: We create one node and mark it as both the front and end of our list.
-
Adding to the end of a non-empty list: We create a node and attach it to the end of the list, then make that our new list end.
-
Adding to the front of a non-empty list: We create a node and attach it to the front of the list, then make that our new list start.
-
Adding somewhere in the middle: We want to add in front of the position denoted by at. We therefore need to start with a loop to search for the node preceding the one pointed to by at. Once we have that, we go ahead with typical linked list pointer swapping.
I do find that getting code like this correct can be tricky, because of the number of pointers that need to be juggled and the number of special cases that often need to be treated separately. The trick, for me, is to draw before-and-after pictures of each case. If I draw a picture of how I expect the linked list to look before an operation and again after it, I can examine the picture to see just which pointers need to be altered to go from one picture to the other, Then I can start to worry about where, in the old picture, I would look to get the values that need to be put into those pointers that are going to change.
1.3 Initializing
The code for the constructors is not complicated.
// for books with single authors
Book::Book (Author a)
{
numAuthors = 1;
first = last = new Book::AuthorNode (a, nullptr);
}
// for books with multiple authors
Book::Book (const Author au[], int nAuthors)
{
numAuthors = 0;
first = last = nullptr;
for (int i = 0; i < nAuthors; ++i)
{
addAuthor(nullptr, au[i]);
}
}
Note that, in the second constructor, where we are adding multiple authors from an array, I have opted to use the addAuthor function that we just implemented rather than writing the pointer manipulation code directly. A lot of programmers would have written the pointer and node manipulation directly into that loop. But we’re going to have to get the code for adding an author to a list written correctly in addAuthor anyway, so why write it (and debug it) twice?
1.4 Clean-Up
It’s expected that an ADT that hides a linked list would clean up all the nodes in that list when required. So here our destructor for a Book clears the list of authors.
void Book::clear()
{
AuthorNode* nxt = nullptr;
for (AuthorNode* current = first; current != nullptr; current = nxt)
{
nxt = current->next;
delete current;
}
numAuthors = 0;
first = last = nullptr;
}
Book::~Book()
{
clear();
}
The clear() function was declared as a private function in the class declaration. Effectively, this is just a “helper” function for us to use here and, as will be seen, one other place. Basically this function runs through the whole linked list of nodes, deleting each one to return its memory to the run-time system for later re-use. It then sets the remaining author-related data members to values indicating that we now have no authors in the list.
The thing to look closely at in this function is the local variable nxt. You can’t clear out a linked list like this:
for (AuthorNode* current = first; current != nullptr;
current = current->next)
{
delete current;
}
because we would have already deleted current before trying to fetch the value current->next. By the time we try to get the value of the next field, it may have already been garbled. It’s a nasty little intermittent error – you might get away with it on 99 tests, then have it fail on the 100th test just when you are demonstrating your code to someone else.
1.5 Copying
We have previously explained why it is important to do a deep copy for this implementation of the Book ADT. This copying will be carried out by the copy constructor and the assignment operator, shown here.
Book::Book (const Book& b)
: title(b.title), numAuthors(0), isbn(b.isbn),
publisher(b.publisher),
first(nullptr), last(nullptr)
{
for (AuthorNode* p = b.first; p != nullptr; p=p->next)
addAuthor(nullptr, p->data);
}
const Book& Book::operator= (const Book& b)
{
if (this != &b)
{
title = b.title;
isbn = b.isbn;
publisher = b.publisher;
clear();
for (AuthorNode* p = b.first; p != nullptr; p = p->next)
addAuthor(nullptr, p->data);
}
return *this;
}
The core of each of these functions is a loop that walks the linked list of the book being copied, adding the authors found there to the end of the book we are copying into. Note the re-use, again, of the addAuthor function for this purpose.
The major differences between these two functions are
-
The copy constructor copies several data members in an initialization list. Because initialization lists are not available outside of constructors, the assignment operator uses ordinary assignments to copy those data members.
This is pretty much a stylistic difference. We could have used assignment of those data members in both functions. The initialization list is slightly more efficient.
-
In the assignment operator, when we copy authors into a book, we want those authors to replace the old list of authors, not to be tacked onto the end of the old list of authors. Hence you can see a call to our helper function clear() used to empty out the list before we start copying into it.
2 Free Lists
How should we deal with nodes that have been removed from a list?
- Obvious choice: delete them
This is what we have already done in our implementation of Book.
void Book::clear()
{
AuthorNode* nxt = nullptr;
for (AuthorNode* current = first; current != nullptr; current = nxt)
{
nxt = current->next;
delete current;
}
numAuthors = 0;
first = last = nullptr;
}
But we can sometimes get better performance by collecting all deleted nodes into a free list — a linked list of nodes that no longer belong to any list.
2.1 Freelist Overview
void Book::removeAuthor (Book::AuthorPosition at)
{
if (at == first)
{
if (first == last)
first = last = nullptr;
else
{
first = first->next;;
}
}
else
{
AuthorNode* prev = first;
while (prev->next != at)
prev = prev->next;
prev->next = at->next;
if (at == last)
{
last = prev;
}
}
delete at; ➀
--numAuthors;
}
Implementing a free list:
-
Where we used to
delete(➀), we instead call adisposeroutine that adds the node to afreelist. -
Where we used to allocate nodes via
new, we instead call anallocroutine that -
returns a node from the
freelist, if possible -
uses
newif the freelist is empty
For example, suppose that we are executing the code shown here.
BooK::AuthorPostion p = L1.find("Baker");
L1.removeAuthor(p);
L2.addAuthor ("Lewis");
L2.addAuthor ("Moore");
L1.addAuthor ("Zeil");
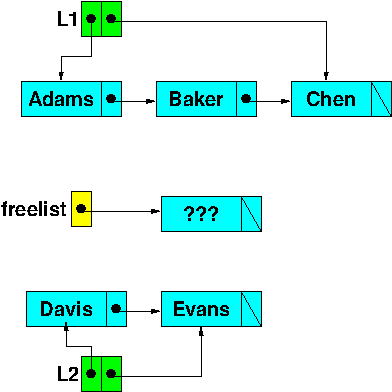
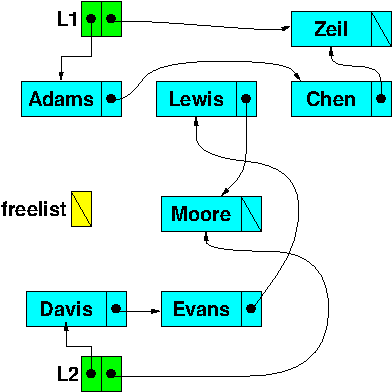
Assume that we starting with this data state:
(Book data members unrelated to the linked lists have been omitted to simplify the picture.)
Freelist: “deleting”
Now suppose we execute the first two lines of code. The “Baker” node will be removed (unlinked) from the list L1 and added to the free list.
BooK::AuthorPostion p = L1.find("Baker");
L1.removeAuthor(p);
L2.addAuthor ("Lewis");
L2.addAuthor ("Moore");
L1.addAuthor ("Zeil");
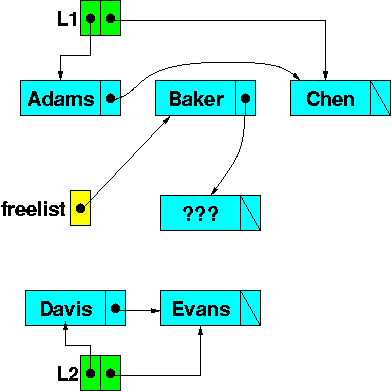
List L1 now contains only “Adams” and “Chen”. The “Baker” node has been placed on the free list. (Of course, given the way that linked lists work, the node itself hasn’t actually moved anywhere. It’s still at the same address it was before. All that has happened is that the links have been rearranged so that it now can be reached from a different list header.)
Freelist: allocation
When we execute the third line, we add a new node (“Lewis”) to the end of list L2, the actual memory for the new node is taken from the front of the freelist.
BooK::AuthorPostion p = L1.find("Baker");
L1.removeAuthor(p);
L2.addAuthor ("Lewis");
L2.addAuthor ("Moore");
L1.addAuthor ("Zeil");
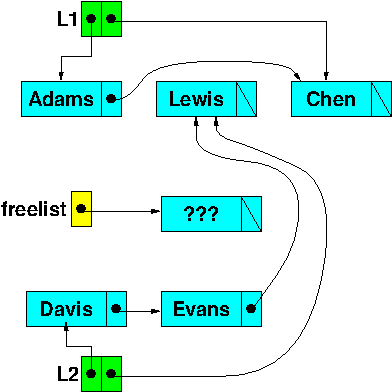
The list L2 now contains 3 nodes. The last of these nodes used to be in L1.
Freelist: allocation
If we again add a node (“Moore”) to a list, the new node is again taken from the free list, and the new data written into it.
BooK::AuthorPostion p = L1.find("Baker");
L1.removeAuthor(p);
L2.addAuthor ("Lewis");
L2.addAuthor ("Moore");
L1.addAuthor ("Zeil");
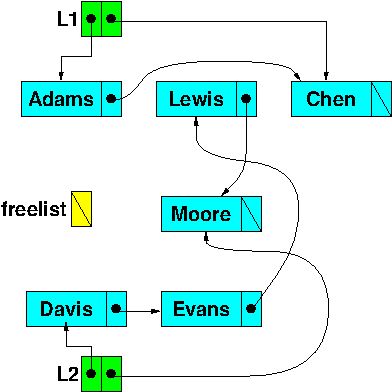
The free list is now empty …
Adding the final node to L1 requires allocating a brand new node since we can’t reuse any from the free list.
BooK::AuthorPostion p = L1.find("Baker");
L1.removeAuthor(p);
L2.addAuthor ("Lewis");
L2.addAuthor ("Moore");
L1.addAuthor ("Zeil");
OK, that’s the idea. How do we implement it?
2.2 Adding a Freelist to the Node Type
We go back to the Book::AuthorNode class and ask this class to provide a freelist.
class Book {
struct AuthorNode {
Author data;
AuthorNode* next;
AuthorNode (const Author& au, AuthorNode* nxt = nullptr)
: data(au), next(nxt)
{}
static AuthorNode* freelist; ➀
static void dispose (AuthorNode* p); ➁
static AuthorNode* alloc (const Author& au, AuthorNode* nxt); ➂
};
⋮
We add 3 new declarations:
➀: the data member freelist, a pointer to the first node in the free list
➁: the dispose function, that adds a node to the free list, and
➂: the alloc function, that returns a pointer to a node that can be added to a list.
Notice that the freelist and alloc are declared as static:
-
static applied to a data member means that this data value is not a member of each individual record, but is shared by all values of this data type.
-
static applied to a function member means the function is not a member of each individual object.
Because static members belong to the entire class rather than to individual objects, they are not called like normal function members:
object.foo(x);
Static members are called like non-member functions:
foo(x);
or
Class::foo(x);
when calling foo from code outside of the Class that contains it.
Why does “static” make sense here? The freelist must obviously be shared, so we only want one freelist for all objects of this class.
As for alloc, it is used to get a node. Since we don’t have a node yet, we could not apply alloc to it, so we can’t make alloc a “normal” member function that operates on existing nodes (i.e., node.alloc() makes no sense).
The implementation of these functions are pretty straightforward.
Book::AuthorNode* Book::AuthorNode::freelist = nullptr; ➀
void Book::AuthorNode::dispose ()
{
// Add *p to the freelist
next = freelist; ➁
freelist = this;
}
Book::AuthorNode* Book::AuthorNode::alloc (const Author& au, AuthorNode* nxt)
{
// Do we have a reusable node on the freelist?
if (freelist != nullptr)
{
// Use the first node in the free list
AuthorNode* result = freelist; ➂
freelist = freelist->next;
result->data = au;
result->next = nxt;
return result;
}
else
{
// Allocate a new node
return new AuthorNode(au, nxt); ➃
}
}
➀ : The freelist header is initialized to null (the list is initially empty).
➁ : When we dispose of an author node, it simply gets put onto the front of the freelist. This is an ordinary linked list manipulation.
➂ : When allocating a new author node, we try to pull the first node off of the freelist and re-use it.
➃ : If, however, the freelist has been emptied, then we fall back on a good old-fashioned new to create a new node.
2.3 Use dispose() and alloc() instead of delete and new
Now, let’s look at how we use the free list functions.
void Book::clear()
{
AuthorNode* nxt = 0;
for (AuthorNode* current = first; current != 0; current = nxt)
{
nxt = current->next;
current->dispose ();
}
numAuthors = 0;
first = last = 0;
}
We search through our entire class. First, we replace any deletes of AuthorNode pointers by calls to dispose.
Then we make a similar search and replace all allocations of nodes via new to calls to the alloc function.
void Book::addAuthor (Book::AuthorPosition at, const Author& author)
{
if (first == 0)
// List is empty - adding to both fitst and last position
first = last = AuthorNode::alloc (author, 0);
else if (at == 0)
{
// Adding to the end of the list
last->next = AuthorNode::alloc (author, 0);
last = last->next;
}
else
{
// Adding somewhere not at the end
AuthorNode* newNode = AuthorNode::alloc(author, (AuthorNode*)at);
if (at == first)
first = newNode;
else
{
AuthorNode* prev = first;
while (prev->next != at)
prev = prev->next;
prev->next = newNode;
}
}
++numAuthors;
}
And that’s all there is to using these routines!
3 Operators new and delete
This is still not the ideal solution.
-
When we “dispose” of a node by putting it on the
freelist, itsvaluefield is not destroyed (i.e., its destructor is never called, so any cleanup it needs to do may never happen). -
When we allocate a node by taking it from the
freelist, itsvaluefield is not initialized (constructed).
We faked that in the example above by passing the two fields as parameters and assigning to them, but there are situations where that would not work or would be rather unwieldy (e.g., if we had a lot more data fields and a lot of different constructors with different combinations of parameters).
This things happened automatically when we used delete & new. We’d like to continue to have that happen.
Solution: C++ lets us define our own new/delete operations for a class.
-
After any call to
new, object is constructed/initialized -
Before any call to
delete, object is destroyed.
3.1 Replace dispose() and alloc() by operators new and delete
So we will replace our dispose and alloc functions by delete and new operators that manipulate the free list in much the same way. (Yes, new and delete are considered operators in C++.)
class Book {
struct AuthorNode {
Author data;
AuthorNode* next;
AuthorNode (const Author& au, AuthorNode* nxt = 0)
: data(au), next(nxt)
{}
static AuthorNode* freelist;
void operator delete(void*);
void* operator new(size_t);
};
⋮
The delete function receives a pointer to the object to be deleted. The new function receives the number of bytes expected of the object and must return a pointer to the newly allocated object.
3.2 Implementing operator new
Implementation is much the same as before.
void* Book::AuthorNode::operator new (size_t sz)
{
// Do we have a reusable node on the freelist?
if (freelist != nullptr)
{
// Use the first node in the free list
AuthorNode* result = freelist;
freelist = freelist->next;
return result;
}
else
{
// Allocate a new node
return malloc(sz);
}
}
The new operator works by returning a node from the freelist if possible. If the freelist is empty, we allocate space for a new node from the heap. We do this by calling the system routine malloc, which requires the number of bytes to be allocated. (Isn’t it fortunate that new gets that number as a parameter!)
3.3 Implementing operator delete
The operator delete works, as did dispose before it, by placing the node at the front of the free list.
void Book::AuthorNode::operator delete (void* p)
{
// Add *p to the freelist
AuthorNode* a = (AuthorNode*)p;
a->next = freelist;
freelist = a;
}
The only catch here is that the pointer being deleted is passed as a void*, so we need to typecast it to AuthorNode* if we want to use any data members of AuthorNode (such as the next field).
3.4 Application code uses new and delete
The code that actually uses the author nodes goes back to the way it was when we used the regular new/delete.
void Book::clear()
{
AuthorNode* nxt = 0;
for (AuthorNode* current = first; current != 0; current = nxt)
{
nxt = current->next;
delete current;
}
numAuthors = 0;
first = last = 0;
}
void Book::addAuthor (Book::AuthorPosition at, const Author& author)
{
if (first == 0)
// List is empty - adding to both fitst and last position
first = last = new AuthorNode (author, 0);
else if (at == 0)
{
// Adding to the end of the list
last->next = new AuthorNode (author, 0);
last = last->next;
}
else
{
// Adding somewhere not at the end
AuthorNode* newNode = new AuthorNode (author, (AuthorNode*)at);
if (at == first)
first = newNode;
else
{
AuthorNode* prev = first;
while (prev->next != at)
prev = prev->next;
prev->next = newNode;
}
}
++numAuthors;
}
The difference is that now this code will be calling our own implementations of those functions.
4 Low-level Storage Management
When you call the “normal” new in C++, it calls the routine malloc in the underlying operating system. When you call the “normal” delete in C++, it calls the routine free in the underlying operating system.
If you were to examine the operating system’s code for malloc and free, you would find that they maintain a free list of blocks of deleted memory.
- The
malloc/freefree list problem is more complicated because blocks are of different sizes.

Suppose a program repeatedly allocates and deletes objects of varying sizes on the heap (e.g., strings):
string *z = new string("Zeil");
string *a = new string("Adams");
string *z = new string("Jones");
The operating system maintains a free list of unallocated blocks of memory on the heap.

If we later do
delete a;
the delete adds a block of memory to the freelist.
The blocks of memory don’t actually move around. They are just managed using linked list nodes that point to the freed blocks of memory.

That was a bit of an oversimplification.
What usually happens is that the opening bytes of each freed block of memory is overwritten by the pointer to the next block in the free list, making it unnecessary to actually maintain a separate list.
Now you can see why some common pointer errors are so dangerous.
-
Dangling pointers: What happens if a block of memory is deleted, added to the free list, and then a dangling pointer access that block of memory?
- If the “access” is read, it may try to interpret the bytes holding the address of the next block of data as part of a valid string or other data.
- If the “access” is write, it may write string data over the the address of the next block of data, breaking the freelist.
-
Deleting the same address twice: This will likely insert a cycle/loop into the free list, losing much of the old freelist and leading to problems on later allocations.
-
Out-of-bounds indexing: If the code to access an array in a valid block of memory goes out of bounds, it can overwrite the size and address link in the following block of memory, corrupting the freelist.
- Or it can overwrite its own size creating a problem when it gets deleted.
4.1 Fragmentation
A new allocation request, e.g.,
string* t = new string("ABC");
requires the OS to search the free list for a block of appropriate size
4.1.1 Searching the free list
-
Common schemes are
-
first fit — choose the first block in the free list that is big enough
-
best fit — choose the block in the free list that is closest to the requested size from among those that are no smaller than the requested size.
If a block is “big enough” but is larger than we need, what do we do with the rest of the block.
4.1.2 Dealing with Inexact size matches
-
Return the whole over-sized block
- Safe, but wastes memory.
-
Oversized blocks are split up
-
When blocks are split up, the remainder is placed back on the free list.
Over time, a program that does many allocations and deletes may find more and more storage wasted on small fragments left on the free list, too small to be useful.
This is called fragmentation.
-
4.2 Performance
-
Free list length could be O(k) where k is the total number of deletes
-
Since each
newrequires a search of that list,newbecomes O(k)-
instead of
O(1), as usually assumed
-
-
deleteis O(1).
This explains why, on occasion, you will find a program that has been running for a long time seems to be getting slower and slower. The free list is being choked with small fragments, so new allocation requests are taking longer and longer.
If such a program is run long enough, it may crash when an allocation request can no longer be satisfied, even though there is more than enough free memory in total.
4.2.1 Compaction
Some malloc/free systems try to reduce or eliminate fragmentation:
- One way is to use compaction: As regions are freed, sort them by address so that adjacent regions of memory are also adjacent within the free list.
-
Adjacent free regions can then be merged to form a single, larger region.
-
Now
deleteis worst case O(k). -
but k might be smaller
-
4.2.2 Uniformly-sized Pools
- Another idea: only allocate regions in selected sizes: 1, 2, 4, 8, 16, 32, 64, …
-
E.g., If a request is made for 10 elements, a 16-element regions is actually returned.
-
A separate free list is kept for each size of region.
-
Larger regions can be split in half to form two smaller regions, when necessary.
-
new and delete remain O(1)
-
but storage utilization may suffer — on average wastes 25% of memory
-
-
Even with all this, you can see why sometimes we would prefer to handle our own storage management. Implementing our own freelist let’s us do allocation and freeing of memory in O(1) time, because all of the data objects on our own freelist will be of uniform size. The more general problem of allocating and freeing memory of different data types of many varying sizes is much harder, and will either have a complexity proportional to the number of prior deletions, or will waste a substantial fraction of all memory.