


Linked Lists
Steven J. Zeil
1 Linked Lists: the Basics
The data abstraction: a sequence of elements
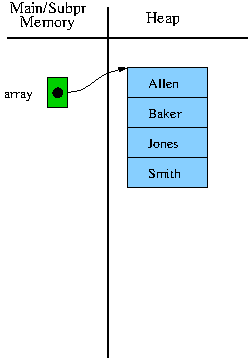 Arrays (and vectors) work by storing elements of a sequence contiguously in memory
Arrays (and vectors) work by storing elements of a sequence contiguously in memory
-
Easy to access elements by number
-
Inserting things into the middle is slow and awkward
An Alternate View
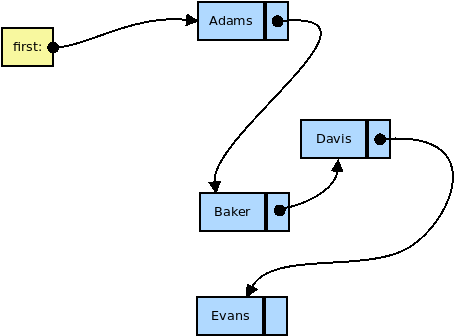
We can approach the same abstraction differently:
-
Linked lists store each element in a distinct node.
-
Nodes are linked by pointers.
- Accessing elements by number is slow and awkward
- Easy to insert things into the middle
List Nodes
template <typename T>
class node {
public:
T nodeValue;
node<T>* next;
node() : next(nullptr)
{}
node (const T& item, node<T>* nextNode = nullptr)
: nodeValue(item), next(nextNode)
{}
};
-
A linked list consists of a number of nodes.
-
Each node provides a data field and a next pointer.
I’ve also added a couple of constructors for convenient initialization of those fields.
1.1 Traversing Linked Lists
We can move from node to node by tracing the pointers:
node<string> *current = head; // assuming that head points
// to the first node
while (current != nullptr)
{
doSomethingWith (current->data);
current = current->next; // move forward one step
}
or
for (node<string> *current = head; current != nullptr; current = current->next)
{
doSomethingWith (current->data);
}
1.1.1 Demo
You can run this demo yourself here.
1.2 Inserting into Linked Lists
We insert by working from the node prior to the insertion point:
//
// Insert value after node p
//
node<string> *newNode = new node<string>;
newNode->info = value;
newNode->link = p->link;
p->link = newNode;
We can also shorten the code above by taking advantage of the constructors we added to the node class:
//
// Insert value after node p
//
node<string> *newNode = new node<string> (value, p->link);
p->link = newNode;
1.3 Removing from Linked Lists
We delete by moving the previous pointer “around” the unwanted node.
//
//Remove value after node p
//
node<string> *q = p->link;
p->link = q->link;
delete q;
The code discussed here is available as an animation that you can run to see how it works.
2 Coding for Linked Lists
We need two data types to build a linked list:
-
The linked list node, which we have already looked at
-
and a header for the entire list:
template <typename Data>
struct LListHeader {
node<Data>* first;
LListHeader();
⋮
};
The header for the entire linked list. In practice, this is sometimes not done not as a separate type, but by simply declaring the appropriate first (a.k.a., front or head) data member as a private member of an ADT.
I’m treating both of these as utilities, not full-fledged ADTs
-
So I’m not going to be as picky about encapsulation and providing operators as I would usually be
-
We would use these to define private date members within “proper” ADTs
2.1 Example: Books with linked lists of Authors
class Book {
public:
Book (Author); // for books with single authors
Book (const Author[], int nAuthors); // for books with multiple authors
Book (const Book& b);
const Book& operator= (const Book& b);
~Book();
std::string getTitle() const { return title; }
void setTitle(std::string theTitle) { title = theTitle; }
⋮
private:
std::string title;
int numAuthors;
std::string isbn;
Publisher publisher;
node<Author>* first;
node<Author>* last;
friend std::ostream& operator<< (const std::ostream& out, const Book& book);
// The "friend" declaration gives this function access to private members of this class
};
std::ostream& operator<< (const std::ostream& out, const Book& book);
2.2 Traversing a Linked List
std::ostream& operator<< (const std::ostream& out, const Book& book)
{
out << book.title << "\nby: ";
const node<Author>* current = book.first;
while (current != nullptr)
{
if (current != book.first)
out << ", ";
out << current->nodeValue;
current = current->next;
}
out << "\n" << book.publisher << ", " << book.isbn << endl;
return out;
}
The highlighted portion is a “typical” linked list traversal.
I often find that when writing this style of while loop, I am so focused on actions required to process the data in the current node that I forget to add the update of current in the final line of the loop body. So, actually, I prefer to write my traversals more like this:
std::ostream& operator<< (const std::ostream& out, const Book& book)
{
out << book.title << "\nby: ";
for (const node<Author>* current = book.first; current != nullptr; current = current->next)
{
if (current != book.first)
out << ", ";
out << current->nodeValue;
}
out << "\n" << book.publisher << ", " << book.isbn << endl;
return out;
}
which helps alleviate the problem of forgetting to update (or to initialize) the current pointer. It also has the advantage of making current a variable that is local to the loop, so that in a more elaborate algorithm, if I have other loops that traverse a linked list, I can re-use the name “current” without worrying about interfering with its use in other parts of the algorithm. Try running this algorithm to be sure that you understand it.
It’s a general rule of good C++ style that variables should be declared in such a way as to make them as local as possible, and that they should always be initialized in their declaration. So the second loop in this section is preferred stylistically over the first (because current is localized to a smaller region of the code). But both of those are preferred to the following, which I often see in student coding:
std::ostream& operator<< (const std::ostream& out, const Book& book)
{
out << book.title << "\nby: ";
const node<Author>* current;
for (current = book.first; current != nullptr; current = current->next)
{
if (current != book.first)
out << ", ";
out << current->nodeValue;
}
out << "\n" << book.publisher << ", " << book.isbn << endl;
return out;
}
which neither localizes the variable current nor initializes it immediately. You might think that I’m being picky about the latter – after all the variable gets initialized in the very next statement. The danger, however, is that your code is not already completed when you are writing these declarations. You might come along later and try to change the code (e.g., switching to the while-loop version) or inserting debugging output and then deleting it again. As changes get made, it’s all too easy to lose or move the initialization code, leaving you with a mess of code that is depending on an uninitialized variable. Bugs caused by uninitialized variables can be some of the hardest to debug.
On the other hand, if you declare and initialize your variables in one step, then if you do something that deletes that statement or that moves it to a later point in the algorithm, you will get an error from the compiler because the various references to it will not compile. You will therefore know immediately that something is wrong and will be given a pretty explicit message explaining the problem.
2.3 Searching a Linked List
To support:
class Book {
⋮
void removeAuthor (const Author& au);
we would need to first locate the indicated author within our list. For that, we do a traversal but stop early if we find what we are looking for.
void Book::removeAuthor (const Author& au)
{
node<Author>* current = book.first;
while (current != nullptr && current->nodeValue != au)
{
current = current->next;
}
if (current != nullptr)
{
// We found the author we were looking for.
⋮
}
}
In this case, I use a while loop instead of the for loop specifically because I need access to the value of current upon leaving the loop - it can’t be local to the loop body.
We’ll fill in the missing non-search portion of this function later.
2.4 Walking Two Lists at Once
Although not really a search, the relational operator code is similar, in that we do a traversal with a possible early exit. But now we have two walk two lists:
// Comparison operators
bool Book::operator== (const Book& b) const
{
if (title != b.title || isbn != b.isbn || publisher != b.publisher)
return false;
if (numAuthors == b.numAuthors)
{
const node<Author>* current = first;
const node<Author>* bcurrent = b.first;
while (current != nullptr)
{
if (!(current->nodeValue == bcurrent->nodeValue))
return false;
current = current->next;
bcurrent = bcurrent->next;
}
return true;
}
else
return false;
}
2.5 Adding to a Linked List
void Book::add (const Author& au)
could be implemented differently depending on whether we want to keep
the authors in the order in which they were added, or in alphabetical
order by author name.
void Book::add (const Author& au)
{
addToEnd (au);
++numAuthors;
}
or
void Book::add (const Author& au)
{
addInOrder (au);
++numAuthors;
}
It might actually be a bit of overkill to treat addToEnd and addInOrder as separate functions, but I’m going to do so in order that we can discuss variants on these later. Note that these functions would need to be declared as (private) function members of the Book class.
2.5.1 addToEnd
void Book::addToEnd (const Author& au)
{
node<Author>* newNode = new node<Author>(au, nullptr);
if (first == nullptr)
{
first = newNode;
}
else
{
// Move to last node
node<Author>* current = first;
while (current->next != nullptr)
current = current->next;
// Link after that node current->next = newNode; } }
Notice how much time and effort is spent just “getting to” the end. (We’ll see a fix for this later.)
2.5.2 addInOrder
void Book::addInOrder (const Author& au)
{
if (first == nullptr)
first = new node<Author>(au, nullptr);
else
{
node<Author>* current = first;
node<Author>* prev = nullptr;
while (current != nullptr && current->data < au)
{
prev = current;
current = current->next;
}
// Add between prev and current
if (prev == nullptr)
first = new node<Author>(au, first);
else
{
addAfter (prev, au);
}
}
}
By the way, it’s only fair to point out that getting all the pointer switching correct that we need to do for these algorithms is not simple. You have to take particular care with the “special cases” of inserting at the start and end of the list, and of inserting into an empty list. Even experienced programmers can struggle with linked list manipulation, particularly with some of the still more complicated variations that we will introduce later.
The key, I find, to getting the code correct is to do a variation on desk checking – draw pictures of the data. In particular, before and after pictures of the list before you make any changes and of how you want it to look when you are done can show you how many different values in your data need to be altered. Then you can draw intermediate pictures to figure out a sensible sequence of steps that will get you from the beginning to the end. Once you have those, it’s much easier to write the code that takes you from one picture to the next.
2.6 Removing from a Linked List
Earlier, we started looking at the idea of removing a node, and saw that we needed to start by searching for the node to be removed:
void Book::removeAuthor (const Author& au)
{
node<Author>* prev = nullptr;
node<Author>* current = book.first;
while (current != nullptr && current->data != au )
{
prev = current;
current = current->next;
}
if (current != nullptr)
{
// We found the author we were looking for.
if (prev == nullptr)
{
// We are removing the first node in the list
first = current->next;
delete current;
}
else
removeAfter (prev);
}
}
void Book::removeAfter (node<Author>* afterThis)
{
node<Author>* toRemove = afterThis->next;
afterThis->next = toRemove->next;
delete toRemove;
}
3 Variations: Headers with First and Last
With the header we have been using so far, …
template <typename Data>
struct LListHeader {
node<Data>* first;
LListHeader();
⋮
};
Adding to (either) end of a list is very common, but compare the amount of work required to add to the front versus adding to the end.
Adding to the front of a list is clearly O(1). But when adding to the end, we have to traverse the entire list, making this O(N) where N is the length of the list.
template <typename Data>
void LListHeader<Data>::addToFront (const Data& value)
{
node<Data>* newNode = new node<Data>(value, first);
first = newNode;
}
template <typename Data>
void LListHeader<Data>::addToEnd (const Data& value)
{
node<Data>* newNode = new node<Data>(value, nullptr);
if (first == nullptr)
{
first = newNode;
}
else
{
// Move to last node
node<Data>* current = first;
while (current->next != nullptr)
current = current->next;
// Link after that node
current->next = newNode;
}
}
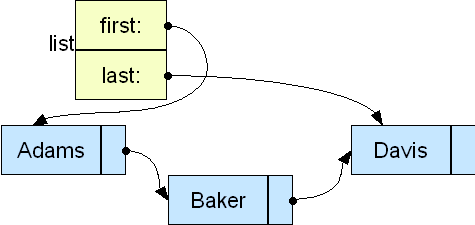
3.1 Adding a Last Pointer
We can speed things up by adding a second pointer in the header:
template <typename Data>
struct LListHeader {
node<Data>* first;
node<Data>* last;
LListHeader();
⋮
The enables (and requires) some change to our operations for adding to the ends.
template <typename Data>
void LListHeader<Data>::addToFront (const Data& value)
{
node<Data>* newNode = new node<Data>(value, first);
first = newNode;
if (last == nullptr)
last = first;
}
template <typename Data>
void LListHeader<Data>::addToEnd (const Data& value)
{
node<Data>* newNode = new node<Data>(value, nullptr);
if (last == nullptr)
{
first = last = newNode;
}
else
{
last->next = newNode;
last = newNode;
}
}
Because we now have direct access to the final element in the list, addToEnd now becomes O(1). The drawback is that all of the add and remove functions become just a little more complicated, because we must now watch for any special cases that affect the last node in the list, and must add code to update last when we do so.
4 Variations: Doubly-Linked Lists
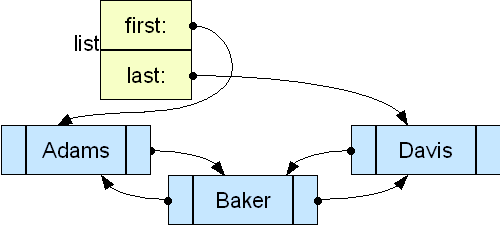
By modifying the node structure:
template <typename Data>
struct dnode
{
Data data;
dnode<Data>* prev;
dnode<Data>* next;
dnode() {next = prev = 0;}
dnode (const Data& d, dnode<Data>* prv = 0, dnode<Data>* nxt = 0)
: data(d), next(nxt), prev(prv)
{}
};
we can
-
Move backwards as well as forward in the list
- by following the
prevpointers
- by following the
-
Easily add in front of a node
4.1 addBefore: Singly and Doubly Linked
Let’s compare the problem of adding a value in front of a known position using both single and doubly-linked lists.
Singly linked:
template <typename Data>
void LListHeader<Data>::addBefore (node<Data>* beforeThis,
const Data& value)
{
if (beforeThis == first)
addToFront (value);
else
{
// Move to front of beforeThis
node<Data>* current = first;
while (current->next != beforeThis)
current = current->next;
// Link after that node
addAfter (current, value);
}
}
Doubly linked:
template <typename Data>
void DListHeader<Data>::addBefore (DListNode<Data>* beforeThis,
const Data& value)
{
if (beforeThis == first)
addToFront (value);
else
{
// Move to front of beforeThis
DListNode<Data>* current = beforeThis->prev;
// Link after that node
addAfter (current, value);
}
}
The singly linked variant is $O(N)$, where $N$ is the length of the list, because in order to add in front of a given node, we have to traverse the list from the beginning up to the node just before the one where we want to insert.
But the doubly linked version needs no such traversal, because we can use the prev link to move backwards in O(1) time.
Of course, now we have almost twice as many pointers to update whenever we add or remove a node, so the code becomes a bit messier and difficult to get correct.
The code discussed here is available as an animation that you can run to see how it works.
5 Variations: Sentinel Nodes
It may be clear by now that much of the difficulty in coding linked lists lies in the special care that must be taken with special cases:
- adding or removing the first node
- adding or removing the last node
- removing the only node (which is simultaneously first and last)
- doing anything with an empty list
Your textbook suggests a way to simplify this coding, by introducing sentinel nodes. A sentinel in a data structure is a reserved position at one end or the other that doesn’t hold “real” data, but is used to help keep algorithms from running off the end of the structure.
A purely empty list with sentinels would look like this.
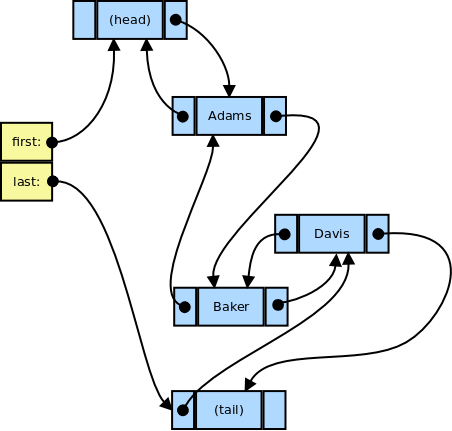
A list with data keeps the data between the sentinels. The (head) and (tail) nodes do not hold data, and we will have to craft the code so that traversals never actually visit those nodes. But when adding or removing “real” data, this structure pretty much eliminates all of those special cases I listed above. A new node or a node to be removed is never going to be first/last/only because the sentinels sit in the first and last position.