

Regular Expressions
CS390, Spring 2024
Abstract
In the prior module, we introduced finite automata as a simple mathematical model of computation. FAs work as language recognizers, allowing us to determine if a given input string belonged to a certain language.
In this module, we focus on the set of languages that can be recognized by FAs. These regular languages are defined via the notation of regular expressions, with which you are probably already familiar.
These lecture notes are intended to be read in concert with Chapter 3 of the text.
1 Regular Languages and Regular Expressions
Remember that a language is a set of strings. We can therefore “operate” on languages using conventional set operators.
We will be exploring a particular set of languages (that is, sets of sets of strings) in this module, the regular languages.
Definition Regular languages over an Alphabet $\Sigma$
If $\Sigma$ is an alphabet, the set $\cal R$ of regular languages over $\Sigma$ is defined as follows.
- The language $\emptyset$ is an element of $\cal R$.
- The language $\{\epsilon\}$ is an element of $\cal R$.
- For every $a \in \Sigma$, the language $\{a\}$ is in $\cal R$.
- For any two languages $L_1$ and $L_2$ in $\cal R$, the three languages
- $L_1 \cup L_2$,
- $L_1 L_2$, and
- $L_1^*$ are elements of $\cal R$.
-
Remember that $\emptyset$ and $\{\epsilon\}$ are not the same thing. The first is a set with zero elements. The second is a set with one element, a string that happens to be empty.
-
Steps 2 and 3 explicitly puts the empty string ($\epsilon$) and all of the single character strings ($\Sigma^1$) into regular languages.
-
Note that it does not say that the empty string and every single character string is in every regular language. For example, if $\Sigma = \{a, b, c\}$, I can have a regular language in which none of the strings contain a $b$. But step 3 of the definition does say that $\{b\}$ is a regular language within the set $\cal R$ of all regular languages.
-
-
Step 4 of the definition says that, if we have two regular languages, we can combine them via concatenation, union, and/or closure to get new regular languages.
From this definition, we can introduce a notation for each of the cases above to allow a compact description of a regular language. This notation will be called regular expressions. You should be familiar with regular expressions as used in a variety of programming contexts. In this course, we will be using a small subset of the richer set of operators that you would want in “practical” r.e. languages:
| Regular Language | operation | Regular Expression |
|---|---|---|
| $\emptyset$ | empty set | $\emptyset$ |
| $\{\epsilon\}$ | empty string | $\epsilon$ |
| $\{\ldots\}$ | set of… | no corresponding notation, use an equivalent expression instead |
| $L_1 L_2$ | concatenation | $r_1 r_2$ |
| $L^*$ | Kleene closure | $r^*$ |
| $L_1 \cup L_2$ | union | $r_1 + r_2$ |
There’s really very little difference between the language operations and the regular expressions except for avoiding the use of set brackets and using the plus sign for unions. That similarity is good, because it leaves us confident that the regular expressions do, indeed, capture the set of regular languages that we have said we are interested in.
The plus sign is also the biggest deviation from programming-style regular expression notations, where the vertical bar | generally denotes unions and the plus is actually a unary operator denoting “one or more repetitions”, as opposed to the “Kleene star” (*) that denotes “zero or more repetitions.”
So, overall, the equivalence between regular languages and regular expressions does seem to hold up.
A note about the precedence of the operators in regular expressions:
- The closure operator $*$ takes precedence over concatenation: $ab^* = a(b^*)$.
- Concatenation takes precedence over the union operator $+$: $ab + cd = (ab) + (cd)$.
2 Applications of Regular Expressions
2.1 Text Utilities
As mentioned earlier, regular expressions (with an expanded set of operators) have long been featured in text processing utilities, particularly in Unix-based operating systems, which, when you get right down to it, is “everything but Windows”, since Linux, Android, OS/X, & IOS are all derived from Unix. You may remember grep and sed from CS252 as two of the more obvious uses of this. Many text editors also support regular expression modes for searching and replacement of text.
Given that these tend to feature an expanded set of operators, you might legitimately question whether these notations are “really” still regular expressions in the sense we have defined them here.
For the most part, you can argue that the new operators are a matter of convenience and can be defined in terms of our more basic operators. For example, the use of + to mean one or more repetitions can be argued away by noting that, for any regular expression r, we can rewrite (r)+ as r(r)*. The latter is perfectly in accord with our basic definition. But if r were long or complicated, the new plus notation might reduce the amount we need to type and reduce the chances of our making a mistake along the way.
Similarly, we can explain away common features like the square bracket notation for grouping characters as a special case of union, and most special symbols like the \s for a whitespace character also as a special case of unions.
There are a few questionable extensions.The ability, for example, to refer back to a string that was matched by a parenthesized sub-expression is decidedly non-regular in search strings, but most programs that allow this extension will use it only in replacement strings during search-and-replace operations.
2.2 Programming Language APIs
At one time, part of the popularity of scripting languages like Perl was their built-in ability to use regular expressions in string handling. As one scripting language after another included regular expression handling, it seemed for a while that one of the defining charactersitics of a “scripting language” as opposed to a “full” or ’production" programming language, was whether or not they included regular expression handling.
Over time, however, the designers of production programmign languages have come to embrace regular expressions. Java introduced them into its 1.4 API as the Pattern class in 2002. Regular expressions were added to C++ as part of the C++11 standard, after having been available for public trial in the Boost libraries for several years.
2.3 Lexical Analysis in Compilers
Soon, we’ll begin looking at grammars, which among other things form the basis for programming language compilation.
But using grammars only to describe real programming languages would be prohibitively difficult. Consider, for example, the fact that one can insert a programming language inline comment (e.g. /* comment */) almost anywhere. So precisely describing something like an if statement would require saying something like:
‘i’ followed by
ffollowed by any combination of whitespace characters and inline comments followed by a ‘(’ followed by any combination of whitespace characters and inline comments followed by an expression followed by any combination of whitespace characters and inline comments followed by a ‘)’ …
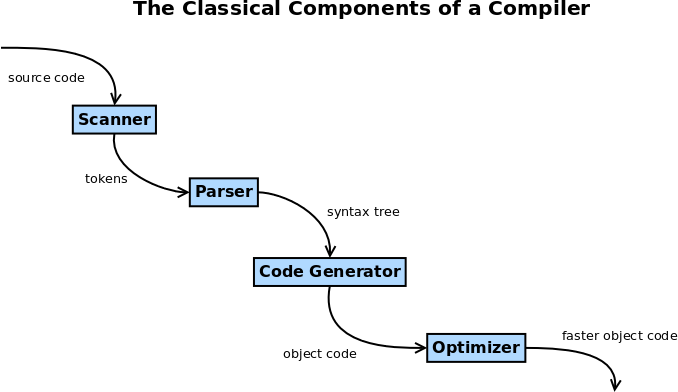
Instead, we generally assume that source code is passed through a scanner or lexical analyzer before we start trying to recognize statement-level structure.
The scanner’s job is to take in source code as a lengthy stream of individual characters and
- Throw out the stuff that doesn’t contribute to the actual code, mainly whitespace characters and comments.
- Group together adjacent sequences of characters into lexemes, a grouping that is in some sense a meaningful, indivisible unit, such as all the characters that make up a single variable name, a single reserved word, or a single numeric constant. This lexeme is then examined to see what “kind” of lexeme it is, and a token is prepared that carries a numerical or enumeration identifier of that kind.
The next phase of the compiler, the parser, will then not have to deal with a long stream of characters but a much shorter stream of tokens. This has two big advantages:
-
It’s easier to describe what kind of structures we want the parser to recognize. An
ifstatement, now would be described simply asan
if(reserved word) token followed by a ‘(’ followed by an expression followed by a ‘)’…Much simpler than what we were looking at before.
-
The number of tokens is orders of magnitude smaller than the number of original characters, both because we have discarded whitespace and comments and because we have reduced multi-character constructs like
aVeryLongVariableNameto a single token.Scanning algorithms are much, much faster than parsing algorithms, so front-loading a lot of this processing onto a scanner winds up speeding up the overall compiler significantly.
Now, what the the relevance of all this compiler stuff to the topic at hand? It turns out that the kinds of lexemes that make up most programming languages can be easily described using regular expressions. That’s not entirely coincidental. A language designer who was foolish enough to design non-regular lexemes would be strongly urged to rethink that design.
Here, for example, is a description of the lexemes for Java. You’ll find most of them to be rather obvious. For example, the regular expression for the reserved word “while” is while (surprise!).
There’s a lot in there, in part because this is, after all, a fairly good-sized programming language and also because this file actually contains code to be run by the scanner when it recognizes a lexeme.
But if you concentrate on the expressions towards the left, you can see the regular expressions in play.
-
The regular expressions for a reserved word are usually trivial. For example the regular expression for the opening word of a while loop is:
while. Couldn’t be simpler!Similarly, most of the operators are, pretty much, their own regular expressions.
-
A more interesting example would be
DecIntegerLiteral = 0 | [1-9][0-9]* | [1-9][_ 0-9]*[0-9]
as the name suggests, this describes a base-10 integer constant. There are three cases, separated by the union | bars. The first case is zero. The second case is one or more digits, the first of which cannot be zero (because multi-digit integers with a leading zero are octal constants), and the third case describes a more obscure rule allowing programmers to put underscore characters inside numbers (e.g., 1_000_000) but not in the first or last position.
In essence, lex, flex, jflex, and other scanner generators translate these regular expressions into FAs, a kind of “mini-language” for each distinct token. The overall scanner is then the union of the those individual token languages, and we’ve seen that taking the union of two FAs leaves us with a regular language recognizable by another FA.
Some scanner generators may then try to convert what is usually an NFA to a DFA. Some may try to minimize the number of states in the DFA (a subject for the next module). The end result, however, is a table of data that serves as the transition table for a FA. it takes only a small amount of code to actually drive a simulated FA using that transition table, and that code is usually very fast.
3 Finite Automata and Regular Expressions
We have already seen that DFAs are equivalent to NFAs (both with and without $\epsilon$-transitions).
Now we will show that every DFA (and, hence, every NFA) can be described by a regular expression, and that every regular expression can be described by an NFA (and, hence by a DFA).
3.1 Every DFA Can be Described by a Regular Expression
Theorem: If $L$ is the language recognized by some DFA $A$, then there is a regular expression $R$ that recognizes $L$.
I’m not going to re-type the proof from your textbook here, but simply comment upon it.
Assume that $A$ has $n$ states and that we re-label those states as $\{1, 2, \ldots n\}$.1
A key idea of this proof will be the regular expressions $R_{ij}^{(k)}$, which we will construct as a regular expression for the strings that would transition from state $i$ to state $j$ without passing through any intermediate node whose state number is greater than $k$. (This restriction affects only the internal or intermediate nodes of the path, but does not limit the “end points” $i$ and $j$ themselves.)
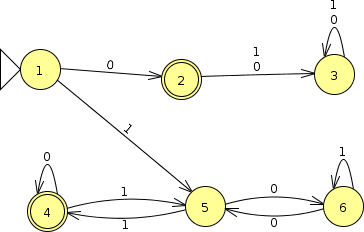
Let’s think about that for a moment. In this FA, if we could find a regular expression $r_1$ for all strings that would take us from state 1 to state 2 (pretty trivial, actually) and another regular expression $r_2$ for all strings that would take us from state 1 to state 4, then the regular expression $r_1 + r_2$ would be a regular expression for the language accepted by this FA.
Thinking about the problem of constructing $r_2$ and how that compares to these $R_{ij}^{(k)}$ sets, you can see, first of all, that we are interested in getting from 1 to 4, so we would be looking for some $R_{1 4}^{(k)}$ expressions. Now, when $k$ is small, the definition of $R_{ij}^{(k)}$ is quite restrictive. There’s no way to get from 1 to 4 without going through state 5, so $R_{1 4}^{(0)}$, $R_{1 4}^{(1)}$, $R_{1 4}^{(2)}$, and $R_{1 4}^{(3)}$ are all impossible, which we denote as $\emptyset$.
We can, however, come up with an expression for $R_{1 4}^{(5)}$, a regular expression for the set of strings that take us from 1 to 4 without passing through node 6: $110^*(110^*)^*$.
But what we need, however, is $R_{1 4}^{(6)}$, the set of strings taking us from 1 to 4 and allowed to pass through any nodes. That’s going to be a bit messier. But the proof will explain how this is done.
So overall, the proof is going to be a structural induction in which we build the overall regular expression we want by building $R_{ij}^{(k)}$ for progressively larger values of $k$, until $k \geq n$.
3.1.1 Base Case
When $k = 0$, we are looking for paths that go from $i$ to $j$ without passing through any other vertex. There’s only a few ways that can happen.
-
If $i = j$, then the empty string $\epsilon$ can be thought of as taking us from $i$ to itself. In addition, we would have to look at “loops” consisting of a single arc from a node to itself.
-
If $i \neq j$, then only transitions directly from $i$ to $j$ would count.
So we can construct $R_{ij}^{(0)}$ without too much trouble.
Think: What would the $R_{ij}^{(0)}$ be for the DFA shown above?
3.1.2 Induction
Can we compute $R_{ij}^{(k)}$ from the $R_{ij}^{(k-1)}$?
Yes. Consider any string recognized by $R_{ij}^{(k)}$. That string would take us through some path from $i$ to $j$ that without passing through any intermediate nodes numbered higher than $k$.
-
Maybe it also doesn’t take us through $k$. In that case, this string is already accepted by $R_{ij}^{(k-1)}$. Hold on to that thought for now.
-
Maybe it does take us through $k$. In that case, as your text explains, we break that path into segments:
- A segment from $i$ to $k$ that does not pass through $k$.
- Zero or more segments from $k$ to $k$ (that do not pass through $k$ on the way).
- A segment from $k$ to $j$ that does not pass through $k$.
But we can express each of those three pieces in terms of the lower-than-k expressions:
- A segment from $i$ to $k$ that does not pass through $k$: $R_{ik}^{(k-1)}$
- Zero or more segments from $k$ to $k$ (that do not pass through $k$ on the way): $\left(R_{kk}^{(k-1)}\right)^*$
- A segment from $k$ to $j$ that does not pass through $k$: $R_{kj}^{(k-1)}$
So we can describe all paths from $i$ to $j$ passing through $k$ at least one time as the concatenation of those three groups of segments:
\[ R_{ik}^{(k-1)} \left(R_{kk}^{(k-1)}\right)^* R_{kj}^{(k-1)} \]
And that means that we can express $R_{i j}^{(k)}$ as
\[ R_{i j}^{(k)} = R_{i j}^{(k-1)} + \left( R_{ik}^{(k-1)} \left(R_{k k}^{(k-1)}\right)^* R_{k j}^{(k-1)} \right) \]
I previously suggested that $R_{1 4}^{(5)}$ in this FA could be described as $110^*(110^*)^*$.
Regular expressions can sometimes be far messier than the corresponding FA, and this is a good example of that.
On the other hand, there are certainly instances where an FA seems more complicated than the corresponding DFA. If, however, we use NFAs instead of DFAs, we can actually do a much more direct structural representation of the NFA. That idea is at the heart of our next important theorem.
3.2 Every Regular Expression Can be Described by a NFA
Moving from FA to regular expressions was fairly hard.
Moving in the other direction, from regular expressions to FAs, it pretty easy.
Theorem: Every language described by a regular expression is also defined by a finite automaton.
The proof is by structural induction, and is quite visual. It consists of demonstrating that
-
every regular expression with 0 operators (i.e., $\emptyset$, $\epsilon$, or $a$ for any single symbol $a$ in $\Sigma$) can be written as a collection of nodes with one incoming transition.
-
every regular expression consisting of an operator (
+,*, or concatenation) applied to one or two operands can be written as a collection of nodes with one incoming transition, at most one outgoing transisition, and that connects to its operands using no more than one input and one output transition.
The base case is summarized by the diagrams in Figure 3.16 of your text.
The inductive case is summarized by the diagrams in Figure 3.16 of your text. You should convince yourself that those diagrams do indeed capture the behavior implied by the three operators.
1: One of the rare instances where computer scientists start counting from one instead of zero!