Note that we don’t need transitions out of the accept state, because the TM halts as soon as we reach an accept state.
Try running this on
010
01010
011001
2.2 Ends with 101
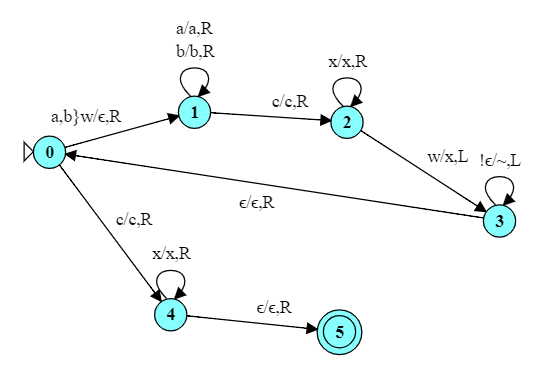
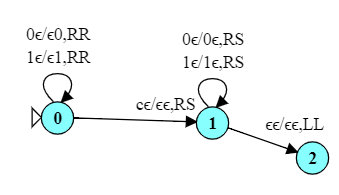
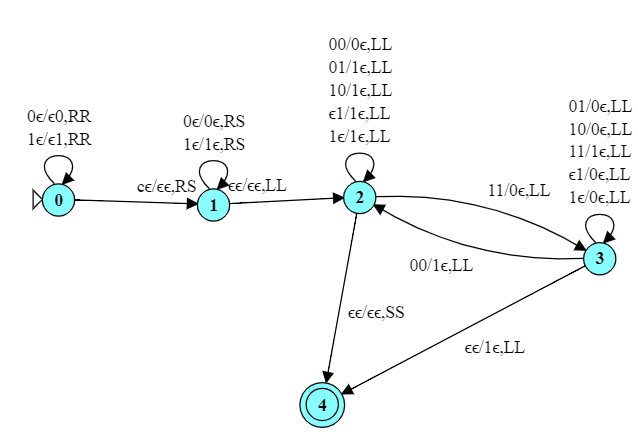
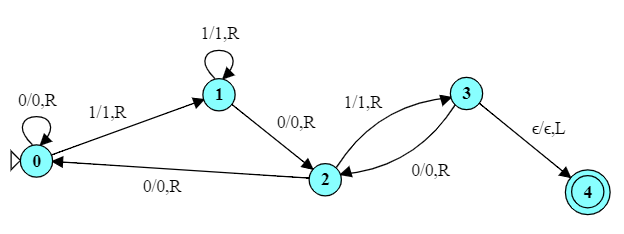
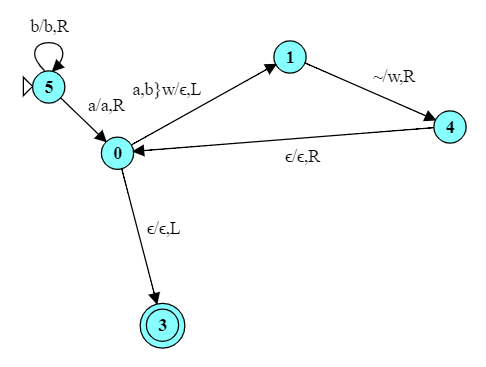
Here is a FA for accepting strings that end with 101.
In this automaton, we can enter the accepting state many times (e.g., 101010) but only accept the string if we are in the accepting state AND have processed all of the input.
Notice the difference in how the accepting state is handled. In a FA, we halt if we reach the end of input and are in a final state. But TMs don’t have the idea of “end of input” – a TM can make any number of passes over its input. A TM halts when it enters a final state regardless of how many symbols it has processed.
In this case, therefore, when we spot a 101, we look to see if we are at the end of the string (input $\epsilon$) and, if so, halt.
But there’s a simpler, arguably more “Turing-machine-style” way to do this. In this TM, state 0 simply moves the head to the end of the string, then states 1…4 move right-to-left to check if the end of the string is “101”.
Try running this on
101
1010
1010101
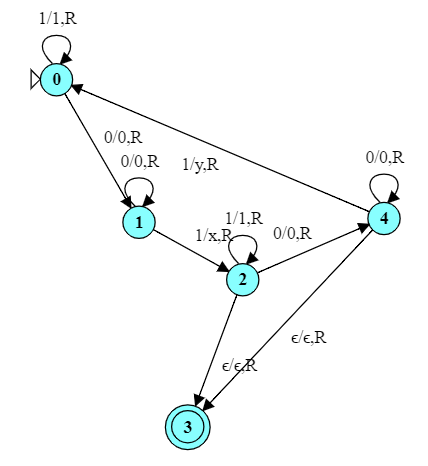
2.3 $0^n1^n$
Now let’s consider a context-free language.
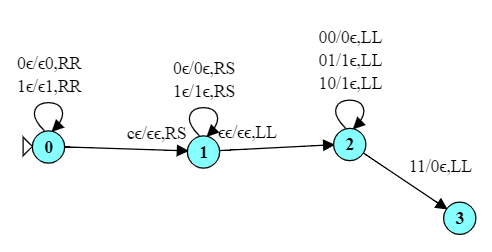
Consider the language of all strings of the form $0^n1^n$, i.e., some number of zeros followed by an equal number of ones. This is a typical “counting” problem for a PDA, as shown to the right.
The TM does not use a stack, but we achieve much the same by “matching” symbols. We will remove pairs of ’0’s and ’1’s until we have no ’0’s left, then make sure that all of the ’1’s are also gone.
Starting from state 0, we erase the leftmost ‘0’.
In state 1, we then skip over any remaining ’0’s, expecting to hit a ‘1’.
When we see a ‘1’, we replace it with an ‘x’.
In state 2 we then run back to the left end of the string and return to state 0 so we can repeat the whole process.
If, in state 0, we are looking at an ‘x’, we make one last pass over the string to make sure we have no ’1’s remaining.
Try running this on
0011
00011
00111
The TMs in this section illustrate a number of “programing style” tips that are worth pointing out to people new to Turing machines:
The TM controller is a deterministic FA. So anything you can do with a DFA, you can translate directly to a TM, never changing anything on the tape. But sometimes TMs can do the same thing in a simpler fashion.
Unlike FAs, a TM can make multiple passes over the input data.
TM’s can make a “pass” over their data both from left-to-right and from right-to-left.
Many TM algorithms spend a lot of time bouncing back and forth from one end of the input string to the other.
Recognizing TMs
Use a combination of inspection and of running test cases on each of the following Turing machines to determine what it does.
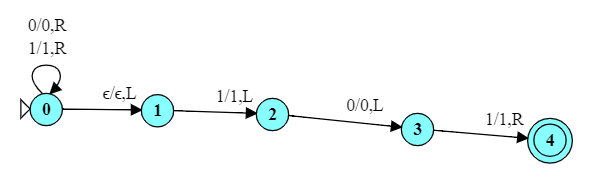
All strings over {0, 1} in which the number “01” pairs is odd.
This is actually a regular language. (The RE would be $1*00*11*(00*11*00*11*)*0*$.) You might have noticed that it processes the input on the tape in a strict left-to-right progression. The only use of the tape is to mark off 01 pairs with a ‘x’ for an odd occurrence and a ‘y’ for even occurrences. And that is purely decorative, because the TM never goes back to look at any of the changed markings. In effect, all of the work is done in the TM’s controller, and that controller is a DFA.
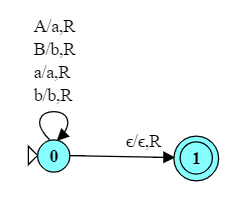
2.5 Recognizing the Function Computed by a TM
Often we think of TMs not so much as acceptors of languages as computers of functions. The input to the function is the initial content of the tape and the output is the final content of the tape when the TM reaches an accepting state.
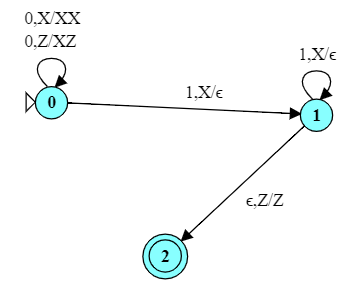
What is the function computed by this TM when presented with inputs over the language {a,b,A,B}* ?
Reveal
If computes the “lower-case equivalent” of a string over {a, b, A, B}.
It shifts all of the characters on the right of its starting position one step to the left, overwriting whatever character the head was originally positioned over.
The interesting thing here is the kind of two-step shuffle carried out in the transitions $q_0 \rightarrow q_1 \rightarrow q_4$, which sees and erases an ‘a’, steps to the left and writes an ‘a’, then steps back to the right into the newly erased position. The transitions $q_0 \rightarrow q_b \rightarrow q_4$, but for ‘b’ instead of ‘a’.
Now, of course, on an infinite tape of empty cells, shifting your entire input one one position to the left has no real effect. But we could use this as a building block or design pattern as part of a larger TM function.
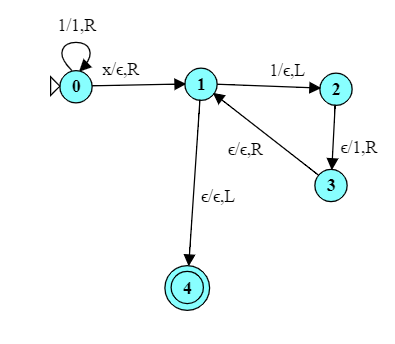
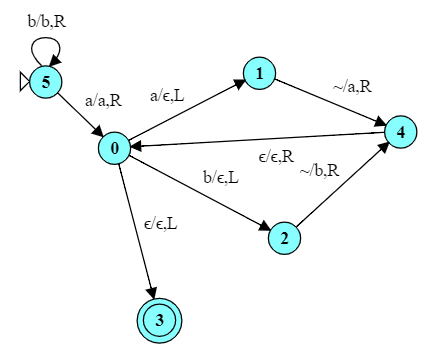
For example, suppose that we had a string over ${a,b}^*$ and that we wanted to erase the first ‘a’. How would you write a TM to do this?
Reveal
We could design a TM that scans until it reaches the first ‘a’, then apply that “shift-left” pattern to move the remainder of the string one step to the left, overwriting and, in effect, deleting the ‘a’.
Try this TM on the input “bbaabab” to see this in action.
There are two changes here compared to our “shift-left” TM:
The new starting state $q_5$, which scans right until we find an ‘a’, then moves into our “shift-left” TM pattern.
The cells to the left of the starting position for the shift-left are not likely to be empty. So, in the transitions $q_1 \rightarrow q_4$ and $q_2 \rightarrow q_4$, instead of matching the input $\epsilon$, I’ve used a shortcut provided by Automat: ‘~’ denoting “any character”.
You may notice a symmetry in our shift-left pattern between the way that ‘a’ and ‘b’ are handled. If we wanted to do a shift-left for a language over three symbols instead of two, we would add another branch similar to $q_0 \rightarrow q_1 \rightarrow q_4$ and $q_0 \rightarrow q_2 \rightarrow q_4$. For a language over four characters, we would add yet another branch. Languages with larger alphabets add more states and transitions to this pattern, making everything just a little bit messier and hard to read.
A shortcut discussed in your text and supported by Automat is to store one character in a “variable”, allowing it’s retrieval later. For example, a transition with an input labelled “a,b}w” means “accept input ‘a’ or ‘b’, storing whichever you actually see in the variable w. Any later transition that mentions ”w" is then assumed to be referring to the variable.
How would you use that to simplify our “delete-the-1st-a” TM?
Reveal
Here is the simplified TM. Try running it on the input “bbaabab” to see this in action.
In the transition $q_0 \rightarrow q_1$, we save the input character into the variable w.
In the transition $q_1 \rightarrow q_w$, we write the saved character onto the tape.
2.7 TMs as Functions 3
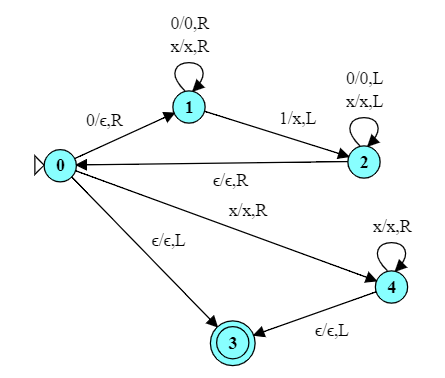
What is the function (over the alphabet $\{a,b,c\}$) computed by this TM?
Hints:
It works from the middle out.
The language is over ${a,b,c}$. But this also uses tape symbols ${A, B, C}$ to denote the “abc” character that have already been “processed”.
At the end of processing, states 5 and 6 rewrite all of the upper-case characters back to their lower-case equivalent.
Reveal
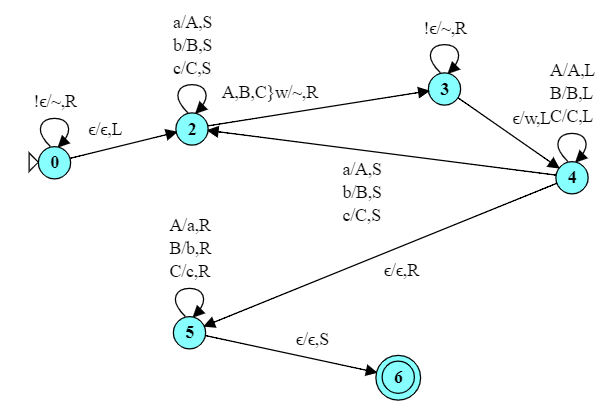
This is a palindrome generator. Given an input string over {a,b,c}, it copies the reverse of that string onto its own end.
For example, to process abc, it
Moves to the right end of the string.
Changes the final ‘c’ to ‘C’: abC
Moves to the right until it hits an empty cell and writes a ‘C’ there: abCC.
Moves to the left until it hits a lower-case letter (‘b’) and changes that to ‘B’: aBCC
Moves to the right until it hits an empty cell and writes a ‘B’ there: aBCCB.
Moves to the left until it hits a lower-case letter (‘a’) and changes that to ‘A’: ABCC
Moves to the right until it hits an empty cell and writes a ‘B’ there: ABCCBA.
Moves to the left looking for a lower-case letter, but hits the left end of the string instead.
Enters state 5, which scans down the string reducing each upper case character to its lower-case equivalent: abccba
These TMs illustrate some more common programming tricks common to TMs:
Shifting data to one side or the other, often to make room to insert a symbol into the middle.
Using special symbols, that may or may not be part of the language’s alphabet, as markers to help the TM navigate.
3 Turing Machines as Language Acceptors
Earlier we saw ways to use TMs to accept languages that we had seen with earlier, less powerful automata.
Next, we can consider problems that could not be solved using the automata we have had before.
3.1 $0^n1^n2^n$
Design a TM to recognize the language of strings of the form $0^n1^n2^n$.
(Although $0^n1^n$ is a CFL and can be recognized by a pushdown automaton, $0^n1^n2^n$ is not context-free and requires a more powerful approach.)
Reveal
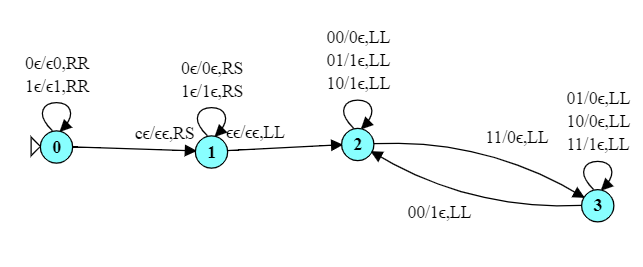
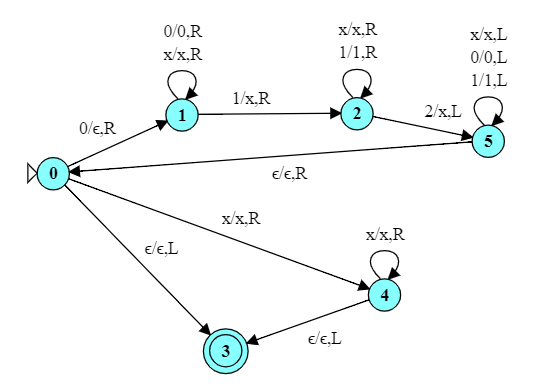
This is a language that is not CF and cannot be accepted by a PDA. But we can recognize this language with a fairly minor change to our TM for $0^n1^n. That TM worked like this:
Starting from state 0, we erase the leftmost ‘0’.
In state 1, we then skip over any remaining ’0’s, expecting to hit a ‘1’.
When we see a ‘1’, we replace it with an ‘x’.
In state 2 we then run back to the left end of the string and return to state 0 so we can repeat the whole process.
If, in state 0, we are looking at an ‘x’, we make one last pass over the string to make sure we have no ’1’s remaining.
This TM inserts one additional state, $q_5$, that does for inputs of ‘2’ what state $q_2$ does for inputs of ‘1’. In essence, we implement a new algorithm:
Starting from state 0, we erase the leftmost ‘0’.
In state 1, we then skip over any remaining ’0’s, expecting to hit a ‘1’.
When we see a ‘1’, we replace it with an ‘x’.
In state 2 we continue moving to the right, skipping over any 1’s we encounter.
When we encounter a ‘2’, we replace it with an ‘x’, then run to the left end of the string and return to state 0 so we can repeat the whole process.
If, in state 0, we are looking at an ‘x’, we make one last pass over the string to make sure we have no ’1’s or ’2’s remaining.
Try executing this on inputs:
001122
00122
0011222
012012
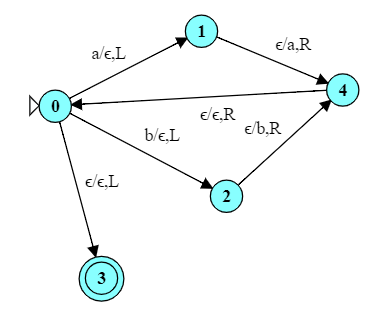
3.2 $\alpha c\alpha$ where $\alpha \in \{a,b\}*$
3.2.1 Basic Implementation
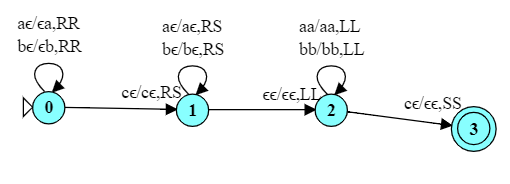
Consider the problem of designing a TM to compare two strings over $\{a,b\}$ to see if they are equal.
All input to the TM must be on the tape, so we could choose to separate the two strings by a blank, e.g.,
aba abb
or by a separator character
abacabb
I’m going to choose the latter.
Another way to view this machine is to say that it recognizes strings over {a,b,c} of the form
\[ \{ \alpha c\alpha | \alpha \in \{a,b\}* \}, \]
which is definitely not a CFL.
Design a TM to recognize this language:
Reveal
First, we can try to figure out an algorithmic approach for doing this
In the transition from $q_0$ to $q_1$, we recognize an ‘a’ or a ‘b’ and save it in the variable w.
$q_1$ moves us forward to the inter-string marker ‘c’.
$q_2$ moves us past any already-matched characters in the second string.
In the transition from $q_2$ to $q_3$, we recognize a match in w to the character encountered in the transition from $q_0$ to $q_1$.
$q_3$ moves us back to the start of the first string so that we can repeat the process.
3.2.2 Using Multiple Tapes
We can get an even simpler (IMO) TM by using multiple tapes.
Solve the same problem using a multi-tape TM.
Reveal
This isn’t quite as simple as we might hope. Our convention is that all input needs to be supplied on the first tape, and so the input will still be presented in the form:
string1cstring2
The procedure in this case is:
Copy the first string onto the second tape.
At the end of this procedure, the head of the first tape will be pointing at ‘c’, the head of the second tape just past the end of the copied first string.
Leave the 2nd tape head where it is, and move the first tape head to the right until we hit the end of the second string.
Now start moving to the left, comparing corresponding characters in the two strings. If they match we keep going. If they don’t match, we fail.
If we reach the beginning of both strings with all matching, we accept.
Whether this is simpler or not than the single-tape approach may be, I suppose, open to debate. After all, trying to envision two tapes is unfamiliar and adds a bit of complication of its own. However, what cannot be denied is that the multi-tape version is faster. Because of the need to repeatedly traverse back and forthe across the entire input, the single-tape machine runs in $O(n^2)$ time (where $n$ is the length of the longer of the two strings). This multi-tape TM makes exactly two passes over the input, and so does the same thing in $O(n)$ time.
4 Turing Machines as Functions
As computer scientists, we are familiar with the fact that numbers and strings of symbols can be encoded in binary (base-2).
Arithmetic in Turing machines is often conducted in an even simpler form: unary encoding, where a single symbol is used (either ‘0’ or ‘1’) and the value of the number is indicated by the length of the string. For example, the decimal number 4 is 100 in binary, and 1111 in unary. The decimal number 6 is 110 in binary, but 111111 in unary.
Unary encoding is often employed for TMs simply because it makes many elementary arithmetic operations nearly trivial
4.1 Unary Form Integer Increment
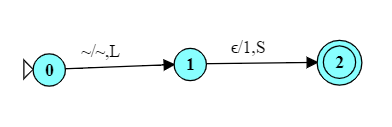
Suppose that a tape contains an integer $k$ in unary form (i.e., a string of 1’s, where the value of the integer is the length of the string. Construct a TM to replace its input by the value of the function $f(k) = k+1$.
Reveal
You may have expected to be more difficult than it really is.
To add 1 to a number written in unary format, we just add another ‘1’ to either end.
Suppose that a tape contains pair of integers $m, k$ in unary form separated by a single ‘x’. Construct a TM to replace its input by the value of the function $f(m,k) = m+k$.
Reveal
All we need to do is to remove the ‘x’ separating the two numbers. Then shift the remaining characters left to fill in the gap.
The convenience of unary does not mean that we can’t do binary arithmetic in TMs.
Suppose that we have two binary integers on a tape, separated by a symbol ‘c’. Design a TM to compute the sum of those two integers.
This will be easiest to do with a multi-tape TM. As in our previous multi-tape example, we will start by copying the first string/number from tape 1 to tape 2, then position the heads of both tapes on the right-most symbol of each string.
After that, we can enact a binary addition, working right to left, in much the way that you would do manually.
For example, given the input tape:
1
1
c
1
1
0
we will split the two inputs onto two tapes like this.
□
1
1
0
□
□
□
1
1
□
We will compute the sum and put it onto the first tape:
1
0
0
1
□
(don’t care)
Reveal
This is the most complicated TM we have attempted so far, so let’s take it in stages.
First, let’s copy the 1st number onto the 2nd tape:
Let’s take this in stages:
Start by copying the 1st number to tape 2. Run this on 11c110 to confirm that it works.
Next, let’s shift the tape head on tape 1 to the end of the 2nd number, and then position both tape heads on the right-most digits.
Run this on 11c110, using single-stepping to watch the movement of the tape heads, to confirm that it works.
Now we are ready to start actually doing addition. If we see two zeros, we write a zero onto the answer in tape 1. If we see a one and a zero, we write a one onto the answer in tape 1. Either way, we then shift the tape heads left to the next higher pair of digits. Of course, that leaves the case of seeing a pair of ones. For that, we would write a ‘0’ and “carry the one”.
The idea of the “carry” reminds us that our prior rules (e.g., $1+0 \rightarrow 1$) only apply when there is no carry. So we will use state $q_2$ to add digits with no carry, and a different state, $q_3$, will enact the rules for addition when we have a carry.
Here we have added the “with carry” addition rules, including the case of adding $0+0$ with a carry, which gives us a sum of $1$ but returns us to the non-carry state $q_2$.
Now it’s time to start thinking about how to end this.
If we are in state 2 (no carry), and looking at two empty cells, then we have finished adding the numbers and can stop.
If we are in state 3 (carry), and looking at two empty cells, then we would need to write the 1 from the carry onto the left of the answer.
If we are in either of those states and see only one empty cell, that means that one of our two numbers has more digits than the other. We would treat those empty cells as if they contained a zero.


 (video)
(video)