Fall 2000: CS 771/871 Operating Systems
[ Home | Class Roster | Syllabus | Status | Glossary | Search | Course Notes]
Lecture 1
Who am I and what is my background in
operating systems?
What is an operating system?
What about this old book?
Is the advanced study of operating systems dead?
What is an advanced operating system course about?
Go over syllabus.
What are distributed systems?
- Distributed
System
-
- A distributed system is a collection of
independent computers that appear to the users of
the system as a single computer (tanenbaum).
Distributed System
should:
- control network resource allocation to allow their use in
the most effective way
- Provide convenient virtual machine
- hide distribution of resources
- provide protection
- provide secure communication (Goscinski)
This is in contrast to centralized computing (timesharing) or
independent PC's.
- Why study them? Because of perceived advantages:
- better price/performance (PCs are
cheap, supercomputers are not)
improved speed (Speed of
light is limit, many operations in parallel)
naturally supports distributed application (banking)
- increased reliability (failures can
be isolated)
- incremental growth (keep old
machines, just add more)
- data sharing (computer supported
cooperative work - or games)
- device sharing (printers, scanners, DVD writers are expensive)
- communications (support groups of
people working together)
- flexibility (match load to idle
machines more easily).
But distributed systems have their disadvantages, chief among
them is the complexity and relative unavailability of <<SOFTWARE>>. Most of the problems of non-distributed systems still
exist, but we have added many new problems to solve in order to
achieve some of the perceived advantages among them are network congestion and rerouting and
security.
Also most distributed
systems complicate the job of the user by forcing them to be
aware of various aspects of the distributed system (Don't you
love URL's).
Software Concepts
The job of the operating system is to mold incalcitrant
hardware into a beautiful virtual machine.
One distinction is based on the degree of autonomy between
processors (tightly vs loosely coupled).
Combinations of hardware and software
- Network OS: high degree of autonomy,
possible different operating systems, few system wide
resources (printers, network file system). Client Server
protocols. User aware of distribution of resources.
RLOGIN, RSH, SETENV DISPLAY, FTP
are examples of explicit user actions which reflect lack
of transparency of location of resources.
On the other hand, NFS makes the location of your files
transparent within the network complex.
- True Distributed OS: single system image
presented to user: virtual uniprocessor. Note how this
contrasts with traditional timesharing systems which make
a single CPU look like many virtual CPUs. Requires:
- Global interprocess communications
- global protection
- global process management
- transparent distributed file access
- Multiprocessor Timesharing OS: tightly
coupled. common ready queue. Shared memory, file system
is like single CPU version, possible specialization of
processors.
QUESTION: why must scheduler run in a critical section?
QUESTION: What else must be run in a critical section?
See table in figure 1.12
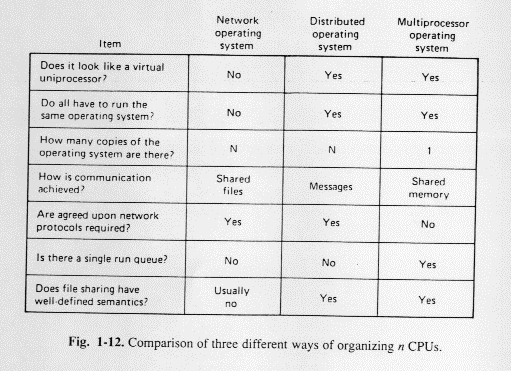
Another way to look at differences is to consider the
traditional hierarchical structure of a centralized OS:
- File Management
- I/O Device Management
- Memory Management
- Process Management
Now consider a network of resources consisting of
- file servers
- printers
- plotters
- scanners
- name servers
- personal computers or workstations
- processors
Now consider different placements of the InterProcess
Communications (IPC) module within the traditional hierarchy.
If between 1 and 2, then File Service can be provided remotely
and transparently.
If between 2 and 3, then shared remote devices are supported
transparently.
If between 3 and 4, then shared memory
If integrated into 4, true distributed OS.
NOTE: one can make access to remote resources appear
transparent by adding software above the OS. This is particularly
easy if the OS has a light weight kernel and exports many of the
management to user level process (like file management, I/O
management). then these modules can utilize the network to access
remote resources.
One of the earliest attempts at a network OS was the National
Software Works, undertaken in the middle 70's.
Consisted of heterogeneous computers connected by ARPANET.
Implementation was entirely at the application level (reminds one
of internet and web browsers, search engines, etc). But developed
a IPC which provided common functionality on diverse systems.
Dealt with addressing (naming) problems which is still a big
issue in distributed systems.
This early attempt had performance problems.
Other early attempts were based on remote procedure calls
(RPC) built on top of a centralized OS with network access
(figure 2-6 Goscinski).
Consisted of the following steps:
- User Process communicates using provided IPC to local
Remote Access System (RAS) with a request.
- Local RAS sends request to an appropriate Remote RAS.
- Remote RAS acknowledges to local RAS
- local RAS transmits acknowledgment to user process with
information to set up direct communication path to remote
RAS.
- User process sends pertinent data to remote RAS.
- which access appropriate resource on remote system
- sends acknowledge to user process
- remote RAS awaits completion of request
- and send acknowledge back to user process.
Consider some of the design tradeoffs.
QUESTION: what other ways to solve?
QUESTION: what are the design issues?
The newcastle connection was an early attempt
at developing a network OS based on the UNIX OS. Used an
extension of the UNIX hierarchical file naming structure to tie
different systems together (loosely coupled).
Draw out the naming structure.
Replaced library routines between user and kernel levels. this
intermediate level communicated with other using RPC.
Because all processes are subjected to intermediate processing
for kernel requests, slows down everybody.
There are no widely used
commercially available distributed OS today, although there are
many networked OS.
So why study? Because the design issues are
important in general and the trend is towards more distributed
systems (LAPLINK, mobile computing). It is the future and parts
of it are already here.
Design Issues:
- Transparency: Hide underlying
distributed implementation. (easier to do at the user
level than the programming level). Different levels of
transparency:
- Location: location of resources unknown
- Migration: resources can move without changing
their names
- Replication: number of copies unknown (cache)
- Concurrency: share resources automatically and
unobtrusively
- Parallelism: programmer unaware of parallel
activity on his behalf
- Flexibility: Unresolved issue:
traditional vs micro
kernel. Microkernel utilizes servers which provide
higher level OS functions. Can customize a set of OS
functions to application. For example, different file
systems (DOS, UNIX, MAC) could be provided services.
- Reliability: If probability of failure
of a single CPU is p, then the probability of n
CPUs failing at the same time is p**n. For
example, if probability of failure is .1 for a single
CPU, then the probability that 3 CPUs fail simultaneously
is .001. Replicated hardware is the key to the
reliability of mission critical systems.
In practice failures may not be independent and in fact
if there are interdependencies between components, the
reliability may even decrease. (in the worst case it is
the probability that at least one component fails -
consider a pipeline architecture which requires all CPUs
to be working to get anything done. Then the probability
that all CPUs are working is (1-p)**n which for
our example is .729.
Availability: is the fraction of time
the system is usable.
Reliability also includes data integrity and security
concerns. (copies of key files increases availability but
may compromise the integrity of the data).
Fault Tolerance: is the ability to
provide service even in the face of system failures.
- Performance: various metrics, some end
user oriented (response time), others resource oriented
(throughput, utilization). Raw numbers (speed of CPU or
network) are often misleading. Benchmarks are frequently
used to compare systems. But makeup of benchmark is
application specific.
Communications is typically the bottleneck.
For parallelism to work must consider the appropriate
grain size.
- Scalability: From LANs to Internet. from
home PCs to smart telephones. Scalability usually implies
eliminating all centralized resource handling.
Distributed algorithms are distinguished by:
- No machine has complete information of system
state
- machines make decisions based on local
information
- failure of one machine will not cause system
failure
- no global clock assumed
One of the fundamental problems in
distributed OS is lack of global state and up-to-date
information.
Chapter 2.
What is a Process?
What is the address space? memory space, set of
shared objects?
Are critical sections important in a distributed
system?
Are the mechanisms described in chapter 2
relevant?
Is non-determinism bad? is it avoidable?
ASSIGNMENT:
- Create a website for your contributions to this course.
send me the URL for this site. On this site add the following:
- Your "classic" definition of what is an
operating system
- Define what an operating system of the future will
do
- Stake a claim in what area(s) you plan to develop
expertise
- Explain why auxiliary variables (section 2.7.3) are
needed? (this is your first homework assignment - e-mail your answer.
Copyright chris wild 1996.
For problems or questions regarding this web contact [Dr. Wild].
Last updated: August 29, 1996.