Fall 2000: CS 771/871 Operating Systems
[ Home | Class Roster | Syllabus | Status | Glossary | Search | Course Notes]
Lecture 4 - Distributed OS
What are distributed systems?
- Distributed
System
-
- A distributed system is a collection of
independent computers that appear to the users of
the system as a single computer (tanenbaum).
Distributed System
should:
- control network resource allocation to allow their use in
the most effective way
- Provide convenient virtual machine
- hide distribution of resources
- provide protection
- provide secure communication (Goscinski)
This is in contrast to centralized computing (timesharing) or
independent PC's.
Distributed systems do not share memory or a clock.
- Why study them? Because of perceived advantages:
- better price/performance (PCs are
cheap, supercomputers are not)
improved speed (Speed of
light is limit, many operations in parallel)
naturally supports distributed application (banking)
- increased reliability (failures can
be isolated)
- incremental growth (keep old
machines, just add more)
- data sharing (computer supported
cooperative work - or games)
- device sharing (printers, scanners, plotters are expensive)
- communications (support groups of
people working together)
- flexibility (match load to idle
machines more easily).
But distributed systems have their disadvantages, chief among
them is the complexity and relative unavailability of <<SOFTWARE>>. Most of the problems of non-distributed systems still
exist, but we have added many new problems to solve in order to
achieve some of the perceived advantages among them are network congestion and rerouting and
security.
Also most distributed
systems complicate the job of the user by forcing them to be
aware of various aspects of the distributed system (Don't you
love URL's).
Software Concepts
The job of the operating system is to mold incalcitrant
hardware into a beautiful virtual machine.
One distinction is based on the degree of autonomy between
processors (tightly vs loosely coupled).
Combinations of hardware and software
- Network OS: high degree of autonomy,
possible different operating systems, few system wide
resources (printers, network file system). Client Server
protocols. User aware of distribution of resources.
RLOGIN, RSH, SETENV DISPLAY, FTP
are examples of explicit user actions which reflect lack
of transparency of location of resources.
On the other hand, NFS makes the location of your files
transparent within the network complex.
- True Distributed OS: single system image
presented to user: virtual uniprocessor. Note how this
contrasts with traditional timesharing systems which make
a single CPU look like many virtual CPUs. Requires:
- Global interprocess communications
- global protection
- global process management
- transparent distributed file access
- Multiprocessor Timesharing OS: tightly
coupled. common ready queue. Shared memory, file system
is like single CPU version, possible specialization of
processors.
QUESTION: why must scheduler run in a critical section?
QUESTION: What else must be run in a critical section?
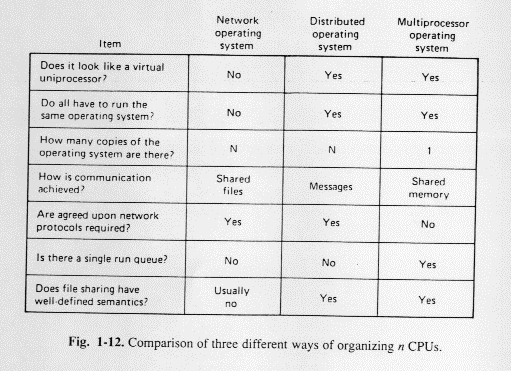
See table in figure 1.12
Another way to look at differences is to consider the
traditional hierarchical structure of a centralized OS:
- File Management
- I/O Device Management
- Memory Management
- Process Management
Now consider a network of resources consisting of
- file servers
- printers
- plotters
- scanners
- name servers
- personal computers or workstations
- processors
Now consider different placements of the InterProcess
Communications (IPC) module within the traditional hierarchy.
If between 1 and 2, then File Service can be provided remotely
and transparently.
If between 2 and 3, then shared remote devices are supported
transparently.
If between 3 and 4, then shared memory
If integrated into 4, true distributed OS.
NOTE: one can make access to remote resources appear
transparent by adding software above the OS. This is particularly
easy if the OS has a light weight kernel and exports many of the
management to user level process (like file management, I/O
management). then these modules can utilize the network to access
remote resources.
One of the earliest attempts at a network OS was the National
Software Works, undertaken in the middle 70's.
Consisted of heterogeneous computers connected by ARPANET.
Implementation was entirely at the application level (reminds one
of internet and web browsers, search engines, etc). But developed
a IPC which provided common functionality on diverse systems.
Dealt with addressing (naming) problems which is still a big
issue in distributed systems.
This early attempt had performance problems.
Other early attempts were based on remote procedure calls
(RPC) built on top of a centralized OS with network access
(figure 2-6 Goscinski).
Consisted of the following steps:
- User Process communicates using provided IPC to local
Remote Access System (RAS) with a request.
- Local RAS sends request to an appropriate Remote RAS.
- Remote RAS acknowledges to local RAS
- local RAS transmits acknowledgment to user process with
information to set up direct communication path to remote
RAS.
- User process sends pertinent data to remote RAS.
- which access appropriate resource on remote system
- sends acknowledge to user process
- remote RAS awaits completion of request
- and send acknowledge back to user process.
Consider some of the design tradeoffs.
QUESTION: what other ways to solve?
QUESTION: what are the design issues?
The newcastle connection was an early attempt
at developing a network OS based on the UNIX OS. Used an
extension of the UNIX hierarchical file naming structure to tie
different systems together (loosely coupled).
Draw out the naming structure.
Replaced library routines between user and kernel levels. this
intermediate level communicated with other using RPC.
Because all processes are subjected to intermediate processing
for kernel requests, slows down everybody.
There are no widely used
commercially available distributed OS today, although there are
many networked OS.
So why study? Because the design issues are
important in general and the trend is towards more distributed
systems (LAPLINK, mobile computing). It is the future and parts
of it are already here.
Design Issues:
- Transparency: Hide underlying
distributed implementation. (easier to do at the user
level than the programming level). Different levels of
transparency:
- Location: location of resources unknown
- Migration: resources can move without changing
their names
- Replication: number of copies unknown (cache)
- Concurrency: share resources automatically and
unobtrusively
- Parallelism: programmer unaware of parallel
activity on his behalf
- Flexibility: Unresolved issue:
traditional vs micro
kernel. Microkernel utilizes servers which provide
higher level OS functions. Can customize a set of OS
functions to application. For example, different file
systems (DOS, UNIX, MAC) could be provided services.
- Reliability: If probability of failure
of a single CPU is p, then the probability of n
CPUs failing at the same time is p**n. For
example, if probability of failure is .1 for a single
CPU, then the probability that 3 CPUs fail simultaneously
is .001. Replicated hardware is the key to the
reliability of mission critical systems.
In practice failures may not be independent and in fact
if there are interdependencies between components, the
reliability may even decrease. (in the worst case it is
the probability that at least one component fails -
consider a pipeline architecture which requires all CPUs
to be working to get anything done. Then the probability
that all CPUs are working is (1-p)**n which for
our example is .729.
Availability: is the fraction of time
the system is usable.
Reliability also includes data integrity and security
concerns. (copies of key files increases availability but
may compromise the integrity of the data).
Fault Tolerance: is the ability to
provide service even in the face of system failures.
- Performance: various metrics, some end
user oriented (response time), others resource oriented
(throughput, utilization). Raw numbers (speed of CPU or
network) are often misleading. Benchmarks are frequently
used to compare systems. But makeup of benchmark is
application specific.
Communications is typically the bottleneck.
For parallelism to work must consider the appropriate
grain size.
- Scalability: From LANs to Internet. from
home PCs to smart telephones. Scalability usually implies
eliminating all centralized resource handling.
Distributed algorithms are distinguished by:
- No machine has complete information of system
state
- machines make decisions based on local
information
- failure of one machine will not cause system
failure
- no global clock assumed
One of the fundamental problems in
distributed OS is lack of global state and up-to-date
information.
Issues in distributed systems
- Global knowledge: at any particular moment, one processes knowledge
of the global state will be out of date.
Possible leading to inconsistency and erroneous actions.
- Must operate in face of dated knowledge
- Must operate without global clocks.
- Arriving at consensus is difficult if not impossible (in general)
- Naming: several problems
- How to create a universally unique name
- How to make that name location transparent
- How do you find where the resource with the name is currently located
- What is the meaning of a copy?
- Compatibility:
- binary level (same instruction sets)
- execution level (object code same)
- protocol level (ftp, rpc, http, rmi, soap)
- Process Synchronization:
- Resource Management: location transparency
- Data Migration
- computational migration
- distributing scheduling
- Security:
- Authentification
- Authorization
- Architecture:
- monolithic kernel
- collective kernel
- object oriented OS
- client server
Communications Primitives
Communications in Distributed Systems
-
Distributed ==> separate computers communicating
-
System Architecture: Layered Abstract Machines
Principle: separation of concerns
-
Some Issues:
-
Virtual circuit or connectionless or both
-
Presentation VS Content
-
Open Systems or Architecture Specific
-
Multimedia?
Seven Layer Peer-to-Peer protocol suite:
-
-
-
-
-
-
-
Allows different physical networks:
Twisted Pair
Coax
Fiber Optic
-
Defines Physical Properties of bits (voltage levels, phase
shifts, etc)
-
Speed of communication and clocking
-
Physical configuration of connectors.
-
Assembles bits into groups (frames, packets)
-
Defines start/end of group
-
Protects against errors (e.g. checksum)
-
Assigns sequence numbers (detects lost frames)
-
Defines control messages for error correction
Probably adds trailer to message for checksum.
Primarily routing in a wide area network.
Some systems are set manually
Others use adaptive algorithms to reduce congestion
QUESTION: What are some of the issues
in adaptive routing?
X.25:
telephony, connection oriented protocol
IP (Internet
Protocol): connectionless
Provides reliable point to point connection (therefore
connection oriented)
ISO provides 5 variants depending on nature of underlying
network and degree of multiplexing.
(DoD has one called TCP (Transmission Control Protocol)
plus connectionless one called UDP (Universal Datagram Protocol))
Provides synchronization and checkpoints with recovery.
Rarely used
Defines Format of information:
-
Character set
-
number representation
-
message formats
What's left:
ATM (Asynchronous Transfer Mode)
OSI was developed in 1970's and reflects older technology.
ATM takes advantage of fast switches and networks.
-
Telephones 4KHz analog channels
-
ARPANET built on 56kbps lines
-
T1 1.5 mbps
-
T3 45 Mbps
-
Evolving 155 Mbps to 1 Gbps (faster than internal disk
drives)
The later speeds imply high speed multiplexing.
Telephone companies: integrate voice and data
Deliema: Voice continuous low bandwidth (circuit switching)
Data: bursty high bandwidth (packet switching)
ATM: international standard
Virtual Circuit: Route saved in switches:
QUESTION: Why keep route in switches?
Small fixed size blocks called CELLS.
QUESTION: Why small? Why fixed size?
Cell Switching: multicasting, multiplexing.
Synchronous Continuous Stream: empty cells fill void
Can use SONET (Synchronous Optical NETwork)
or SDH (Synchronous Digital Hierarchy) used by telephone
companies.
SONET: 9 x 90 byte frame, of 810 bytes, 36 overhead
transmitted every 125microseconds = 51 Mbps (OC-1)
OC-n and OC-nc used to more bandwidth.
ATM uses OC3c (155.520 Mbps) and OC12c (622.080Mbps).
2.5 Gbps coming.
Telephones might use ISDN (64kbps)
Again a compromise:
Europe - small to avoid echo suppressers
Americans - big for efficiency
Result: 48 byte + 5 header
Does not fit nicely into 774 SONET data payload
Header contains (figure 2-5):
-
GFC (4 bits) Generic Flow Control (unused)
-
VPI (8) Virtual Path Id (used for grouping end-to-end)
-
VCI(16) Virtual channel Id
-
Payload Type(3): data, control
-
CLP(1): priority
-
CRC(8) checksum on header only
VPI/VCI reflect assigned route on call setup and change at switch to reflect
next hop, VPI allows a group of connections destined for the same place to be
rerouted together.
Networks are becoming too fast for typically computer OS interaction at the
cell level.
Adaptation maps packets into cells.
Four classes of traffic:
-
constant bit rate (audio/video)
-
variable but bounded delay
-
Connection Oriented
-
Connectionless data
Computer Industry didn't like and drafted AAL5 (SEAL - Simple and Efficient
Adaptation Layer). Distinguishes last cell which contains packet length and
packet checksum.
Computer connect to switches which can connect to other switches. virtual
circuit sets route in each switch during setup.
Requires fast switching speeds (3microsecond for OC3), with parallel input
and output ports. Problem if two inputs need same output.
May drop cells but must deliver others in order received.
Can queue but only temporary congestion relieve possible.
Different solutions depending on nature of traffic streams, may use statistical
analysis.
QUESTION: How fast does an OC12c switch need to be?
2.5Gbps?
High Bandwidth but Physical Delays require rethinking of protocols for flow
control and error handling and bandwidth utilization.
Asymptotically utilized bandwidth approaches 0 while waiting for speed of
light transmission.
Question: How is this akin to the length limit on
Ethernet?
Flow control may become rate control (a-priori
agreements).
Sliding window protocols leads to low utilization (see
calculation).
Maybe should centralize applications with keystroke
per cell from user to application. Has architectural implications.
Conclusion: Potential increase in network
bandwidth may not easily be realized: Active area of research and development.
Some Calculations of effects of high speed
networks
Consider a 1Gbps network connecting Norfolk and San
Francisco.
ATM cells arrive every 56 nanoseconds.
Transmission latency is approx. 2/3 speed of light = 15 milliseconds one way.
Implies there are 15 megabits in the pipeline before the first bit is received.
What if the receiver cannot buffer this much and rejects?
What if I require an ACK message after every 1,000 bits?
Effective transfer rate is 1 microsecond to stuff bits into pipe, 15
milliseconds transfer latency, less than a microsecond to stuff ACK back into
pipe (assuming no processing delays), another 15 milliseconds transfer latency =
1000 bits every 30.002 milliseconds or 33 bps!
If increase packet to 1,000,000 bits, transfer rate is
about 33Kbs (still a long way from 1 Gbps).
Clearly requiring an ACK frequently greatly reduces
usable bandwidth.
Let's start with an appealing simple model.
Server processes which provide service to client processes.
Communications is request/reply
connectionless and asynchronous.
Requires only three layers: physical, datalink, request/reply.
Can be implemented with two procedures (send and receive).
Procedure calls hide distributed nature of service (except perhaps in
addressing). Looks like local procedure call. (see example fig2-9)
There can be different kinds of services provided (another set of design
issues - but outside realm of OS).
Not just client server issues
What is the unit of addressing? machine, process, port, service?
Question: What is static? what is Dynamic?
Are processes given fixed names (numbers)?
Question: Can I run multiple server processes? Why would I
want to?
Are processes given global names or are they machine specific?
Question: How to coordinate global names?
What is wrong with machine specific?
How does internet work its addressing for WWW?
What is the permanence of addresses?
If global, how to route to proper machine?
Could use name server?
Question: what if name server needs to move?
Assigning random addresses?
Question: who assigns? centralized/distributed
How to rout?
How client know address?
Distinguish: Name of service (dry cleaners), location
(address) of service, and instantiation of server (clerk behind counter, process
running on machine).
Question: what about competing servers?
Blocking vs Non-blocking transmission
Also called synchronous/asynchronous.
For both send and receive
Synchronous is easiest to program but async allows
process to do other things while waiting.
Async requires polling or interrupts (call-backs)
programmed into system.
Another complication: timeouts to handle transmission
failures of certain types.
Buffered vs Non-buffering transmission
Who supplies message buffer and when?
How big is it?
What if message sent before server issues "receive" call?
What if server handles many clients? How to receive all potential messages.
kernel could buffer in anticipation call to "receive".
This could be the processes mailbox.
Could block sender if no buffer available.
Who guarantees delivery: application or system (OS or network)?
Question: How does OS know which messages are requests and
which are replies?
Should the reply be acknowledged?
| Type |
From |
To |
Description |
| Request |
Client |
Server |
Service Request |
| Reply |
|
Client |
Reply |
| ACK |
Either |
Other |
ACK previous packet |
| Are You Alive? |
Client |
Server |
see if crashed |
| I Am Alive |
Server |
Client |
has not crashed |
| Try Again |
Server |
Client |
no capacity |
| Address Unknown |
Server |
Client |
no process |
Last two are needed to distinguish between hard and soft failures
Homework:
compare this to WWW client/server protocol. Due one week.
Client/server has strong message passing flavor
Like doing I/O(read and write information from network).
Question: why do we need the concept of disk storage at all? why I/O?
Remote Procedure Calls (RPC)
procedure call which transparently executes on remote
machine
- How is normal procedure call implemented? (Figure
2-17)
- call by value
- by reference
- by copy/restore - difference from call by
reference
- New issues
- different address spaces (scoping)
- possibly different architectures
- crashes
RPC:Analogy
with system calls which masquerade as procedure calls
- Client stub is called as normal procedure
- Assembles parameters into message to remote server
- Traps to kernel for message passing
- Server stub receives message
- unpacks parameters from message
- makes normal procedure call on behalf of client
process
- After call, server stub packs result in message
- Traps to kernel to send reply back to client
- Client stub receives message
- Unpacks results into output parameters
- returns as normal procedure call
client/server request/reply hidden in library stubs
- Different formats
- Different byte orders
- Different data types
Could use a canonical form (network standard).
Problem: possibly inefficient between like machines
Could indicate which format used and let server translate if necessary.
- Forbid (not transparent)
- Copy object referenced
Question: what about user defined data structures
What if size of structure is unknown
- transfer values as needed
what about global variables?
Question: Why is figure 2-22 stateless? What does that mean? How to make it
more like UNIX file services?
When server starts up, it exports its interface to a binder which registers
the services provided.
- name
- version number (why)
- unique ID (allows several servers)
- handle (ethernet or IP address etc)
- authentication
Client stub needs to import first time called to get handle to send message.
Overhead may be a problem
- Cannot locate server: return error
- Request message lost : set timer and resend (watch duplicates)
- Reply lost : who notices, is operation idempotent?
- server crashes after request : difficult to determine if request was acted
upon
- At least once semantics: try and try again
- at most once: don't try again
- exactly once: not possible in general (printing, bank transfers)
- client crashes after request
- Extermination: client logs requests on stable
storage, orphan killed
what about nested RPCS? network partition prevents killing
- Reincarnation: Each time client boots it set epoch number
- Gentle reincarnation: try locate client first
- Expiration: request expire restart must be longer than expiration
period
What about orphans which have initiated other tasks, perhaps at a later
time?
what if orphan has locks on resources?
Also how to report failures to client (return codes, exceptions) which may
not be there for single CPU system (and hence not allowed for in the procedure
spec).
- connection or connectionless
- general purpose protocol or not
- stop-n-wait (acks) or blast or selective repeat
- flow control (overrun errors)
- What about ACKing replies?
- copying between user and kernel spaces can be a big factor
remember that each layer adds its own headers
might be able to able to use virtual memory hardware to avoid copy
- Timer Management: need not be precise (could be polled by kernel)
See critical path analysis fig 2-27.
- Global Variables
- weakly typed languages (C allows unbounded parameters to be passed).
- Complex data structures with pointers
- Printf in C
- Given file servers for read and write, what are pipes?
could have read (only) servers or write only but ends of pipe are problems
- terminal servers sometimes want to interrupt client
- What about group servers? (for fault tolerance)
RPC semantics
- At least once: if succeeds, at least one machine executed the call
- Exactly once: is succeeds, exactly one machine executed it
- At most once: no side effects allowed on abnormal termination
Panzeieri and Srivastava Correctness condition
Let Ci be a RPC call and Wi its execution on some
machine.
Since the "Wi" can share data, the correctness condition is
C1 -> C2 implies W1 -> W2
where -> means "happens after"
Why not use a message instead of RPC?
What about passing procedures as arguments?
- Addressing supported by network
- Multicasting - problem if cycles possible
- broadcasting
- unicasting
- predicate addressing (e.g. look for idle machines)
- Closed vs Open groups
- Peer vs Hierarchical
- Membership services
- lost members
- late join
- reforming groups
- atomicity
- message ordering (need global time ordering)
RPC not suitable abstraction
ISIS is a synchronous system (events happen sequentially in same order on all
machines).
Since events are not instantaneous, interweaving is possible
Two events can be causally related, otherwise concurrent
Virtual synchrony means if two messages are
causally related, all processes must receive them in the same (correct) order).
- ABCAST: loose synchrony
- Sender A assign time stamp (monotonically increasing number)
- each receiver picks own timestamp greater than any previous one sends
to A
- A selects max of those received and send it in Commit message
- CBCAST: virtual synchrony
- each process contains last message number received form all other
processes.
- This vector is incremented in the process's own location and sent with
message
- processes can compare its own vector against sent vector to determine
if any messages received by other processes are pending. (figure 2-38).
Copyright chris wild 1996.
For problems or questions regarding this web contact [Dr.
Wild].
Last updated: September 04, 1996.
Copyright chris wild 1996.
For problems or questions regarding this web contact [Dr.
Wild].
Last updated: September 04, 1996.
Copyright chris wild 1996.
For problems or questions regarding this web contact [Dr. Wild].
Last updated: August 29, 1996.