


Resolving Collisions
Steven J. Zeil
OK, we’ve got our hash functions. They’re not perfect, so we can expect collisions. How do we resolve these collisions?
There are two general approaches:
-
Open Hashing: The hash table performs as an “index” to a set of structures that hold multiple items.
-
Closed Hashing: The keys are stored in the table itself, so we have to search for an open slot within the table.
1 Open Hashing
Historically, one of the most common approaches to dealing with collisions has been to use fixed size buckets, e.g., an array that can hold up to k (some small constant) elements.
The problem with this is that if we get more than k collisions at the same location, we still need to fall back to some other scheme.
So instead, we’ll look at separate chaining, in which the hash table is implemented as an array of variable sized containers that can hold however many elements that have actually collided at that location.
-
Typical choices for this container would be a linked list (which is where the term “chaining” actually comes from) or a tree-based set.
-
Although these containers are variable size, some people still call them “buckets”.
1.1 Implementation
template <class T,
int hSize,
class HashFun,
class CompareEQ=equal_to<T> >
class hash_set
{
typedef list<T> Container;
public:
hash_set (): buckets(hSize), theSize(0)
{}
⋮
private:
vector<Container> buckets;
HashFun hash;
CompareEQ compare;
int theSize;
};
We’ll illustrate separate chaining as a vector of linked lists of elements.
This template takes more parameters than usual. The purpose of the parameters T and hSize should be self-evident.
HashFun is a functor class used to provide the hash function hash.
CompareEQ is another functor class, used to provide an equality comparison (like the less-than comparators used in std::set and std::map). This defaults to the std functor class equal_to, which uses the T class’s == operator.
1.1.1 Finding the Bucket
private:
Container& bucket (const T& element)
{
return buckets[hash(element) % Size];
}
This utility function locates the list that will contain a given element, if that element really is somewhere in the table.
1.1.2 Searching the Set
Now we use the bucket() function to implement the set count() function.
int count (const T& element) const
{
const Container& theBucket = bucket(element);
return (find_if(theBucket.begin(),
theBucket.end(),
bind1st(compare, element))
== theBucket.end()) ? 0 : 1;
}
First we use bucket() to find the list where this element would be. Then we search the list for an item equal to element.
1.1.3 Inserting into the Set
The insert code is quite similar.
void insert (const T& element)
{
Container& theBucket = bucket(element);
Container::iterator pos =
find_if(theBucket.begin(), theBucket.end(),
bind1st(compare, element));
if (pos == theBucket.end())
{
theBucket.push_back(element);
++theSize;
}
else
*pos = element;
}
We use bucket() to find the list, then search the list for the element we want to insert. If it’s already in there, we replace it. If not, we add it to the list.
1.1.4 Removing from the Set
And erase follows pretty much the same pattern.
void erase (const T& element)
{
Container& theBucket = bucket(element);
Container::iterator pos =
find_if(theBucket.begin(), theBucket.end(),
bind1st(compare, element));
if (pos != theBucket.end())
{
theBucket.erase(pos);
--theSize;
}
}
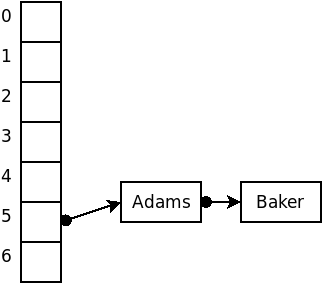
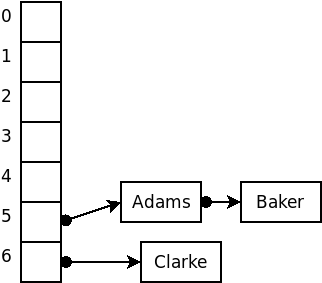
For example, suppose that we wished to insert the strings
Adams, Baker, Clarke, Doe, Evans
into a hash structure using an array size of 7 and, for the sake of example, a terrible hash function that simply uses the size of the strings.
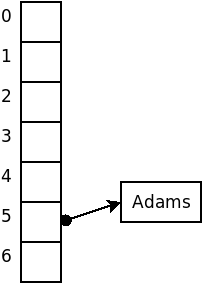
We start with an array of empty linked list headers.
Our first input, “Adams”, according to our bad hash function, hashes to location 5.
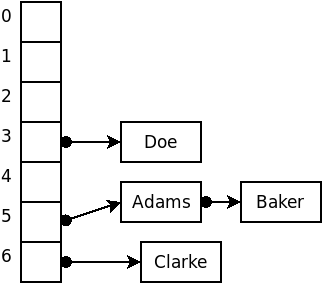
  | 1 of 6 |   |
The code discussed here is available as an animation that you can run to see how it works. (This demo deliberately uses an awful hash function, the length of the string, so that you will have a chance to see lots of collisions taking place.)
You might take note that, as the chains grow longer, the search times become more “sequential search” like. Of course, if we increased the table size, we would hope that the data elements would be dispersed across the larger table, making the average list length shorter. So there is a very direct tradeoff here between memory use (table size) and speed.
1.2 Complexity of Separate Chaining
Suppose we have inserted $N$ items into a table of size hSize.
-
In the worst case, all $N$ items will hash to the same list, and we will be reduced to doing a linear search of that list: $O(N)$. (Your text uses sets instead of lists for the buckets, which would reduce this cost to $O(\log N)$.) On the other hand, the use of sets requires that the data elements support a
<comparison instead of (or in addition to) the==comparison required with list buckets. -
In the average case, we assume that the N items are distributed evenly among the lists. Since we have
Nitems distributed amonghSizelists, we are looking at $O\left(\frac{N}{\mbox{hSize}}\right)$.
If hsize is much larger than N, and if our hash function uniformly distributes our keys, then most lists will have 0 or 1 item, an the average case would be approximately $O(1)$. But if $N$ is much larger than hSize, we are looking at an $O(N)$ linear search sped up by a constant factor (hSize), but still $O(N)$. So hash tables let us trade space for speed.
2 Closed Hashing
In closed hashing, the hash array contains individual elements rather than a collection of elements. When a key we want to insert collides with a key already in the table, we resolve the collision by searching for another open slot within the table where we can place the new key.
enum HashStatus { Occupied, Empty, Deleted };
template <class T>
struct HashEntry
{
T data;
HashStatus info;
HashEntry(): info(Empty) {}
HashEntry(const T& v, HashStatus status)
: data(v), info(status) {}
};
Each slot in the hash table contains one data element and a status field indicating whether that slot is occupied, empty, or deleted.
2.1 Implementation
template <class T, int hSize, class HashFun,
class CompareEQ=equal_to<T> >
class hash_set
{
public:
hash_set (): table(hSize), theSize(0)
{}
⋮
private:
int find (const T& element, int h0) const
⋮
vector<HashEntry<T> > table;
HashFun hash;
CompareEQ compare;
int theSize;
};
The hash table itself consists of a vector/array of these HashEntry elements.
Collisions are resolved by trying a series of locations, $h_{\mbox{0}}$, $h_{\mbox{1}}$, $h_{\mbox{hSize-1}}$, until we find what we are looking for. These locations are given by
\[ h_{i}(\mbox{key}) = (\mbox{hash}(\mbox{key}) + f(i)) % \mbox{hSize} \]
where $f$ is some integer function, with $f(0)=0$. We’ll look at what makes a good $f$ in a little bit.
With these locations, the basic idea is
-
Searching: try cells $h_{i}(\mbox{key}), i=0, 1, \ldots$ until we find the key we want or an empty slot.
-
Inserting: try cells $h_{i}(\mbox{key}), i=0, 1, \ldots$ until we find the same key, an empty slot, or a deleted slot. Put the new key there, and mark the slot “occupied”.
-
Erasing: try cells $h_{i}(\mbox{key}), i=0, 1, \ldots$ until we find the key we want or an empty slot. If we find the key, mark that slot as “deleted”.
2.1.1 find()
Here’s a “utility” search function for use with closed hashing. It takes as parameters the element to search for and the hash value of that element.
int find (const T& element, int h0) const
{
unsigned h = h0 % hSize;
unsigned count = 0;
while ((table[h].info == Deleted ||
(table[h].info == Occupied
&& (!compare(table[h].data, element))))
&& count < hSize)
{
++count;
h = (h0 + f(count)) % hSize;
}
if (count >= hSize
|| table[h].info == Empty)
return hSize;
else
return h;
}
The loop condition is fairly complicated and bears discussion. There are three ways to exit this loop:
-
If we hit an “Empty” space (i.e., not “Deleted”, and not “Occupied”)
-
If we hit an “Occupied” space that has the key we’re looking for
-
If we have tried
hSizedifferent positions. (There’s no place else to look!)
2.1.2 Searching a Set
With that utility, search operations like the set count() are easy. We simply compute the hash value and then call find. Then we check to see if the element was found or not.
int count (const T& element)
{
unsigned h0 = hash(element);
unsigned h = find(element, h0);
return (h != hSize) ? 1 : 0;
}
2.1.3 Removing from a Set
void erase (const T& element)
{
unsigned h0 = hash(element);
unsigned h = find(element, h0);
if (h != hSize)
table[h].info = Deleted;
}
The code to remove elements is just as simple. We compute the hash function and try to find that element. If it’s found, we mark that slot “Deleted”.
2.1.4 Adding to a Set
Inserting is a bit more complicated.
bool insert (const T& element)
{
unsigned h0 = hash(element);
unsigned h = find(element, h0); ➀
if (h == hSize) {
unsigned count = 0;
h = h0;
while (table[h].info == Occupied ➁
&& count < hSize)
{
++count;
h = (h0 + f(count)) % hSize;
}
if (count >= hSize)
return false; // could not add
else
{
table[h].info = Occupied;
table[h].data = element;
return true;
}
}
else { // replace
table[h].data = element;
return true;
}
}
-
➀ Because this is a set (and not a multiset) we first do an ordinary search to see if the element is already there.
-
➁ If not, we need to find a place to put it. The loop that does this looks a lot like the
findloop, but unlikefind, we stop at the first “Deleted” or “Empty” slot.
In the other searches, we had kept going past “Deleted” slots, because the element we wanted might have been stored after an element that was later erased. But now we are only looking for an unoccupied slot in which to put something, so either a slot that has never been occupied (“Empty”) or a slot that used to be occupied but is no longer (“Deleted”) will suffice.
2.2 Choosing f(i)
The function f(i) in the find and insert functions controls the sequence of positions that will be checked. On our $i^{\mbox{th}}$ try, we examine position
\[ h_{i}(\mbox{key}) = (\mbox{hash}(\mbox{key}) + f(i)) % \mbox{hSize} \]
int find (const T& element, int h0) const
{
unsigned h = h0 % hSize;
unsigned count = 0;
while ((table[h].info == Deleted ||
(table[h].info == Occupied
&& (!compare(table[h].data, element))))
&& count < hSize)
{
++count;
h = (h0 + f(count)) % hSize;
}
if (count >= hSize
|| table[h].info == Empty)
return hSize;
else
return h;
}
The most common schemes for choosing $f(i)$ are
-
linear probing
-
quadratic probing
-
double hashing
2.2.1 Linear Probing
\[ f(i)=i \]
If a collision occurs at location h, we next check location (h+1) % hSize, then (h+2) % hSize, then then (h+3) % hSize, and so on.
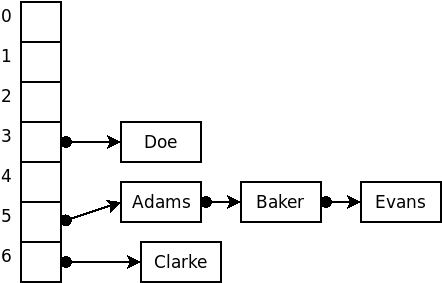
Again, suppose that we wished to insert the strings
Adams, Baker, Clarke, Doe, Evans
into a hash structure using an array size of 7 and, for the sake of example, a terrible hash function that simply uses the size of the strings.
| | 1 of 6 | |
The code discussed here is available as an animation that you can run to see how it works.
Some things to look for:
-
Note how easy it is for keys to “clump up” in contiguous blocks.
-
From the initial setup, try removing Baker, then searching for Davis, then adding Smith. Can you see why “Deleted” slots must be treated differently depending upon whether we’re looking for an existing element or looking for a place to insert a new one?
2.2.2 Quadratic Probing
\[ f(i)=i^2 \]
If a collision occurs at location h, we next check location (h+1) % hSize, then (h+4) % hSize, then then (h+9) % hSize, and so on.
This function tends to reduce clumping (and therefore results in shorter searches). But it is not guaranteed to find an available empty slot if the table is more than half full or if hSize is not a prime number.
Again, suppose that we wished to insert the strings
Adams, Baker, Clarke, Doe, Evans
into a hash structure using an array size of 7 and, for the sake of example, a terrible hash function that simply uses the size of the strings.
| | 1 of 6 | |
The code discussed here is available as an animation that you can run to see how it works.
Try adding and removing several items with the same hash code so that you can see the difference in how collisions are handled in the linear and quadratic cases.
2.2.3 Double Hashing
\[ f(i) = i*h_{\mbox{2}}(\mbox{key}) \]
where $h_{\mbox{2}}$ is a second hash function.
If a collision occurs at location h, and $h2 = h_2 (\mbox{key})$,we next check location (h+h2) % hSize, then (h+2*h2) % hSize, then then (h+3*h2) % hSize, and so on.
This also tends to reduce clumping, but, as with quadratic hashing, it is possible to get unlucky and miss open slots when trying to find a place to insert a new key.
Again, suppose that we wished to insert the strings
Adams, Baker, Clarke, Doe, Evans
into a hash structure using an array size of 7 and, for the sake of example, $h_1$ will still be size of the strings. $h_2$ will be an equally bad function that only looks tat the starting letter, and assigns $A=1, B=2, C=3\ldots$.
| | 1 of 6 | |
2.3 Analysis of Closed Hashing
Define $\lambda$,the load factor of a hash table, as the number of items contained in the table divided by the table size. In other words, the load factor measures what fraction of the table is full. By definition, $0 \leq \lambda \leq 1$.
-
Given an ideal collision strategy, the probability of an arbitrary cell being full is $\lambda$.
-
Consequently, the probability of an arbitrary cell being empty is $1-\lambda$
-
The average number of cells we would expect to examine before finding an open cell is therefore $\frac{1}{1-\lambda}$.
Now, we never look at more than hSize spaces, so, for an ideal collision strategy, finds and inserts are, on average,
\[ O\left(\min\left(1/(1-\lambda), \mbox{hSize}\right)\right) \]
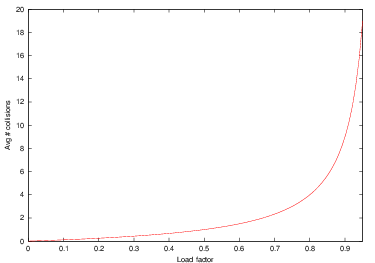
Here you can see the behavior of the function $1/(1-\lambda)$ as the load factor, $\lambda$ increases.
If the table is less than half full ( $\lambda < 0.5$ ), then we are talking about looking at, on average, no more than 2 slots during a search or insert. That’s not bad at all. But as $\lambda$ gets larger, the average number of slots examined grows toward hSize (and, if the table is getting full, then N is approaching hSize, so we are once again degenerating toward O(N) behavior).
So, the rule of thumb for hash tables is to keep them no more than half full. At that load factor, we can treat searches and inserts as $O(1)$ operations. But if we let the load factor get much higher, we start seeing $O(N)$ performance.
Of course, none of the collision resolution schemes we’ve suggested is truly ideal, so keeping the load factor down to a reasonable level is probably even more important in practice than this idealized analysis would indicate.
And quadratic probing does tell us that it is guaranteed to work if the table size is a prime number and if $\lambda < 2$, so if we are going to keep the table no more than half-full anyway, quadratic probing winds up being an attractive choice.