


Sharing Pointers and Garbage Collection
Steven J Zeil
Swearing by Sharing
We’ve talked a lot about using pointers to share information, but mainly as something that causes problems.
- We have a pretty good idea of how to handle ourselves when we have pointers among our data members and don’t want to share.
In that case, we rely on implementing our own deep copying so that every “container” has distinct copies of all of its components.
For some data structures, this is OK. If we are using a pointer mainly to give us access to a dynamically allocated array, we can copy the entire array as necessary. In the example shown here, we would want each catalog to get its own distinct array of books. So we would implement a deep copy for the assignment operator and copy constructor, and delete the allBooks pointer in the destructor.
- But not every data structure can be treated this way.
- Sometimes, sharing is essential to the behavior of the data structure that we want to implement.
- Most applications that involve graphs rely on lots and lots of pointer-based sharing.
1 Shared Structures
In this section, we will call out three examples that we will explore further in the remainder of the lesson. All three involve some degree of essential sharing.
1.1 Singly Linked Lists

We’ll start with a fairly prosaic example. In its simplest form, a singly linked list involves no sharing, and so we could safely treat all of its components as deep-copied.
1.1.1 SLL Destructors
In particular, we can take a simple approach of writing the destructors — if you have a pointer, delete it:
struct SLNode {
string data;
SLNode* next;
⋮
~SLNode () {delete next;}
};
class List {
SLNode* first;
public:
⋮
~List() {delete first;}
};
Problem: stack size is $O(N)$ where $N$ is the length of the list.
-
If a List object gets destroyed, its destructor will delete its first pointer. That node (Adams in the picture) will have its destructor called as part of the delete, and it will delete its pointer to Baker. The Baker node’s destructor will delete the pointer to Davis. At then end, we have successfully recovered all on-heap memory (the nodes) with no problems.
-
Now, this isn’t really ideal. At the time the destructor for Davis is called, there are still partially executed function activations for the Baker and Adams destructors and for the list’s destructor still on the call stack, waiting to finish. That’s no big deal with only three nodes in the list, but if we had a list of, say, 10000 nodes, then we might not have enough stack space for 10000 uncompleted calls. So, typically, we would actually use a more aggressive approach with the list itself:
Alternative: Destroy the List, not the Nodes
struct SLNode {
string data;
SLNode* next;
⋮
~SLNode () {/* do nothing */}
};
class List {
SLNode* first;
public:
⋮
~List()
{
while (first != 0)
{
SLNode* next = first->next;
delete first;
first = next;
}
}
};
This avoids stacking up large numbers of recursive calls.
- Many operating systems allocate a relatively limited area of memory for the call stack, so this is a non-trivial improvement.
1.1.2 First-Last Headers

But now let’s consider one of the more common variations on linked lists.
-
If our header contains pointers to both the first and last nodes of this list, then we can do O(1) insertions at both ends of this list.
-
Notice, however, that the final node in the list is now “shared” by both the list header and the next-to-last node.
FLH SLL Destructor
So, if we were to extend our basic approach of writing destructors that simply delete their pointers:
struct SLNode {
string data;
SLNode* next;
⋮
~SLNode () {delete next;}
};
class List {
SLNode* first;
SLNode* last;
public:
⋮
~List() {delete first; delete last;}
};
Then, when a list object is destroyed, the final node in the list will actually be deleted twice.
Deleting the same block of memory twice can corrupt the heap (by breaking the structure of the system free list) and eventually cause the program to fail.
1.2 Doubly Linked Lists
Doubly Linked Lists

Now, let’s make things just a little more difficult.
If we consider doubly linked lists, our straightforward approach of “delete everything” is really going to be a problem.
DLL Aggressive Deleting
struct DLNode {
string data;
DLNode* prev;
DLNode* next;
⋮
~DLNode () {delete prev; delete next;}
};
class List {
DLNode* first;
DLNode* last;
public:
⋮
~List() {delete first; delete last;}
};
-
When a list object is destroyed, it will start by deleting the first pointer.
- That node (Adams) will delete its next pointer (pointing to Baker).
- That second node will delete its prev pointer (Adams). 7
-
Now we’ve deleted the same node twice, potentially corrupting the heap.
- But, worse, the Adam node’s destructor will be invoked again.
- It will delete its next pointer, and we will have deleted the Baker node a second time.
-
Then the Baker node deletes its prev pointer again.
Deleting and Cycles
We’re now in an infinite recursion,
-
which will continue running until either the heap is so badly corrupted that we crash when trying to process a delete,
-
or when we finally fill up the activati0on stack to its maximum possible size.
What makes this so much nastier than the singly linked list?
- It’s the fact that not only are we doing sharing via pointers, but that the various connections form cyclesdoc:graphBasics#paths) in which we can trace a path via pointers from some object eventually back to itself.
1.3 Airline Connections
Airline Connections

Lest you think that this issue only arises in low-level data structures, let’s consider how it might arise in programming at the application level.
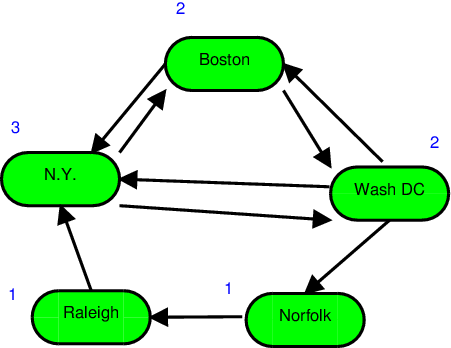
This graph illustrates flight connections available from an airline.
Aggressively Deleting a Graph
If we were to implement this airport graph with Big 3-style operations:
class Airport
{
⋮
private:
vector<Airport*> hasFlightsTo;
};
Airport::~Airport()
{
for (int i = 0; i < hasFlightsTo.size(); ++i)
delete hasFlightsTo[i];
}
we would quickly run into a disaster.
Deleting the Graph
Suppose that we delete the Boston airport.
-
Its destructor would be invoked, which would delete the N.Y. airport and Wash DC airports.
-
Let’s say, for the sake of example, that the NY airport is deleted first.
-
-
The act of deleting the pointer to the NY airport causes its destructor to be invoked, which would delete the Boston and Wash DC airports.
-
But Boston has already been deleted.
-
If we don’t crash right away, we will quickly wind up deleting Wash DC twice.
-
-
In fact, we would wind up, again, in an infinite recursion among the destructors.
This should not be a big surprise. Looking at the graph, we can see that it is possible to form cycles.
- In fact, if there is any node in this graph that doesn’t participate in a cycle, there would be something very wrong with our airline.
Either we would have planes piling up at some airport, unable to leave; or we would have airports that run out of planes and can’t support any outgoing flights.
The Airline
Now, you might wonder just how or why we would have deleted that Boston pointer in the first place.
So, let’s add a bit of context.
- The airport graph is really a part of the description of an airline:
class AirLine { ⋮ string name; map<string, Airport*> hubs; }; AirLine::~Airline() { for (map<string, Airport*>::iterator i = hubs.begin; i != hubs.end(); ++i) delete i->second; }
The AirLine Structure

-
The map hubs provides access to all those airports where planes are serviced and stored when not in flight, indexed by the airport name.
- Not all airports are hubs.
-
An airport that is not a hub is simply one where planes touch down and pick and discharge passengers while on their way to another hub.
Suppose that PuddleJumper Air goes bankrupt.
- It makes sense that when an airline object is destroyed, we would delete those hub pointers.
- But we’ve seen that this is dangerous.
Can We Do Better?
Now, that’s a problem. But what makes this example particularly vexing is that it’s not all that obvious what would constitute a better approach.
- Let’s consider some other changes to the airline structure.
Changing the Hubs

Suppose that Wash DC were to lose its status as a hub.
Even though the pointer to it was removed from the hubs table, the Wash DC airport needs to remain in the map.
Changing the Connections

On the other hand, if Wash DC were to drop its service to Norfolk, one might argue that Norfolk and Raleigh should then be deleted, as there would be no way to reach them.
- But how could you write code into your destructors and your other code that adds and removes pointers that could tell the difference between these two cases?
2 Garbage Collection
Objects on the heap that can no longer be reached (in one or more hops) from any pointers in the activation stack (i.e., in local variables of active functions) or from any pointers in the static storage area (variables declared in C++ as “static”) are called garbage.
Garbage Example
-
In this example, if we assume that the airline object is actually a local variable in some function, then Norfolk and Raleigh appear to be garbage.
-
Unless there’s some other pointer not shown in this picture, there’s no way to get to either of them.
-
-
Being garbage is not the same thing as “nothing points to it”.
-
Raleigh is garbage even though something is pointing to it. Nonetheless, there is no way to get to Raleigh from the non-heap storage.
-
Garbage Collection
Determining when something on the heap has become garbage is sufficiently difficult that many programming languages take over this job for the programmer.
The runtime support system for these languages provides automatic garbage collection, a service that determines when an object on the heap has become garbage anf automatically scavenges (reclaims the storage of) such objects.
Java has GC
The programming Java, for example, looks very similar to C++. A lot of code written in one of these languages will work in the other.
But, in Java, there is no delete operator.
Java programmers use lots of pointers,1 many more than the typical C++ programmer.
But Java programmers never worry about deleting anything. They just trust in the garbage collector to come along eventually and clean up the mess.
C++ Does Not Have GC
Automatic garbage collection really can simplify a programmer’s life. Sadly, C++ does not support automatic garbage collection.
- But how is this magic accomplished?
- Why doesn’t C++ support it?
- What can C++ programmers do about it?
That’s the subject of the remainder of this section.
2.1 Reference Counting
Reference counting is one of the simplest techniques for implementing garbage collection.
-
Keep a hidden counter in each object on the heap. The counter will indicate how many pointers to that object exist.
-
Each time we reassign a pointer that used to point at this object, we decrement the counter.
-
Each time we reassign a pointer so that it now points at this object, we increment the counter.
-
If that counter ever reaches 0, scavenge the object.
2.1.1 Reference Counting Example

For example, here’s our airline example with reference counts.
Now, suppose that Wash DC loses its hub status…




  | 1 of 5 |   |
2.1.2 Reference Counted Pointers in C++
Implementing reference counting requires that we take control of pointers.
-
To properly update reference counts, we would need to know whenever a pointer is assigned a new address (or null), whenever a pointer is created to point to a newly allocated object, and whenever a pointer is destroyed.
-
Now, we can’t do that for “real” pointers in C++.
- But it is quite possible to create an ADT that looks and behaves much like a regular pointer.
- And, by now, we know how to take control of assignment, copying, and destroying of ADT objects.
C++ now provides such an ADT — they are called “smart” pointers.
shared_ptr<T> p (new T());
This declares p to be a smart pointer to a reference-counted object of type T.
-
Actually two blocks of storage are allocated – one to hold the
Tobject and one to hold an associated reference counter; -
When we copy shared pointers to one another, the reference counters get updated automatically.
-
If a reference counter drops to zero, then the object on the heap and its reference counter are destroyed.
Important: You have to commit fully to using shared pointers on the objects they manage. You cannot have ordinary pointers to an object simultaneously while you also have
shared_ptrs to the same objects.Mixing ordinary and shared pointers will likely leave you with dangling ordinary pointers when the shared pointer decides to scavenge an object, eventually causing your program to crash.
2.1.3 Example: A Reference-Counted Singly Linked List
Starting from:
#include <string>
using namespace std;
struct SLNode {
string data;
SLNode* next;
⋮
SLNode (string d = string(), SLNode* nxt = nullptr)
: data(d), next(nxt)
{}
~SLNode () { }
};
class List {
SLNode* first;
public:
⋮
~List()
{
while (first != 0)
{
SLNode* next = first->next;
delete first;
first = next;
}
}
void add(string s)
{
first = new SLNode(s, first);
}
};
we can change all uses of SLNode* to shared_ptr<SLNode>:
#include <string>
#include <memory>
using namespace std;
struct SLNode {
string data;
shared_ptr<SLNode> next;
SLNode (string d = string(), shared_ptr<SLNode> nxt = nullptr)
: data(d), next(nxt)
{}
⋮
~SLNode () {/* do nothing */}
};
class List {
shared_ptr<SLNode> first;
public:
⋮
~List()
{ }
void add(string s)
{
first = shared_ptr<SLNode>(new SLNode(s, first));
}
⋮
};
And we no longer have to worry about explicitly deleting our unneeded nodes.
2.1.4 Is it worth the effort?
-
Reference counting is fairly easy to implement.
-
Unlike the more advanced garbage collection techniques that we will look at shortly, it can be done in C++ because it does not require any special support from the compiler and the runtime system.
-
-
There’s a problem with reference counting, though.
-
One that’s serious enough to make it unworkable in many practical situations.
-
The Case of the Disappearing Airline
Let’s return to our original airline example, with reference counts.
-
Assume that
- the airline object itself is a local variable in a function and that
- we are about to return from that function.
-
That object will therefore be destroyed, and its reference counted pointers to the three hubs will disappear.
| | 1 of 2 | |
What went wrong? Let’s look at our other examples.
Ref Counted SLL
Here is our singly linked list with reference counts.
 Assume that the list header itself is a local variable that is about to be destroyed.
Assume that the list header itself is a local variable that is about to be destroyed.

| | 1 of 2 | |
Ref Counted DLL
Now let’s look at our doubly linked list.

Again, let’s assume that the list header itself is a local variable that is about to be destroyed.

| | 1 of 2 | |
Reference Counting’s Achilles Heel
So two of our last three examples failed when trying to use refe3rence counting.
What’s the common factor between the two failures?
-
It’s the cycles!
If the pointers form a cycle, then the objects in that cycle can never get a zero reference count, and reference counting will fail.
-
Reference counting won’t work if our data can form cycles of pointers.
- And, as the examples discussed here have shown, such cycles aren’t particularly unusual or difficult to find in practical structures.
So a more general approach is needed.
2.2 Mark and Sweep
Mark and sweep is one of the earliest and best-known garbage collection algorithms.
-
It works perfectly well with cycles, but
-
requires some significant support from the compiler and run-time support system.
Assumptions
The core assumptions of mark and sweep are:
-
Each object on the heap has a hidden “mark” bit.
-
We can find all pointers outside the heap (i.e., in the activation stack and static area)
-
For each data object on the heap, we can find all pointers within that object.
-
We can iterate over all objects on the heap
The Mark and Sweep Algorithm
With those assumptions, the mark and sweep garbage collector is pretty simple:
void markAndSweep()
{
// mark
for (all pointers P on the run-time stack or
in the static data area )
{
mark *P;
}
//sweep
for (all objects *P on the heap)
{
if *P is not marked then
delete P
else
unmark *P
}
}
template <class T>
void mark(T* p)
{
if *p is not already marked
{
mark *p;
for (all pointers q inside *p)
{
mark *q;
}
}
}
The algorithm works in two stages.
- In the first stage, we start from every pointer outside the heap and recursively mark each object reachable via that pointer.
(In graph terms, this is a depth-first traversal of objects on the heap.)
- In the second stage, we look at each item on the heap.
- If it’s marked, then we have demonstrated that it’s possible to reach that object from a pointer outside the heap.
- It isn’t garbage, so we leave it alone (but clear the mark so we’re ready to repeat the whole process at some time in the future).
- If the object on the heap is not marked, then it’s garbage and we scavenge it.
- If it’s marked, then we have demonstrated that it’s possible to reach that object from a pointer outside the heap.
Mark and Sweep Example

As an example, suppose that we start with this data.
Then, let’s assume that the local variable holding the list header is destroyed.














| | 1 of 16 | |
Assessing Mark and Sweep
In practice, the recursive form of mark-and-sweep requires too much stack space.
- It can frequently result in recursive calls of the mark() function running thousands deep.
- Since we call this algorithm precisely because we are running out of space, that’s not a good idea.
Practical implementations of mark-and-sweep have countered this problem with an iterative version of the mark function that “reverses” the pointers it is exploring so that they leave a trace behind it of where to return to.
- Even with that improvement, systems that use mark and sweep are often criticized as slow.
The fact is, tracing every object on the heap can be quite time-consuming. On virtual memory systems, it can result in an extraordinary number of page faults. The net effect is that mark-and-sweep systems often appear to freeze up for seconds to minutes at a time when the garbage collector is running. There are a couple of ways to improve performance.
2.3 Generation-Based Collectors
Old versus New Garbage
In many programs, people have observed that object lifetime tends toward the extreme possibilities.
-
temporary objects that are created, used, and become garbage almost immediately
-
long-lived objects that do not become garbage until program termination
Generational GC
Generational collectors take advantage of this behavior by dividing the heap into “generations”.
-
The area holding the older generation is scanned only occasionally.
-
The area holding the youngest generation is scanned frequently for possible garbage.
- an object in the young generation area that survives a few garbage collection passes is moved to the older generation area
The actual scanning process is a modified mark and sweep. But because relatively few objects are scanned on each pass, the passes are short and the overall cost of GC is low.
To keep the cost of a pass low, we need to avoid scanning the old objects on the heap. The problem is that some of those objects may have pointers to the newer ones. Most generational schemes use traps in the virtual memory system to detect pointers from “old” pages to “new” ones to avoid having to explicitly scan the old area on each pass.
2.4 Incremental Collection
Incremental GC
Another way to avoid the appearance that garbage collection is locking up the system is to modify the algorithm so that it can be run one small piece at a time.
-
Conceptually, every time a program tries to allocate a new object, we run just a few mark steps or a few sweep steps,
-
By dividing the effort into small pieces, we give the illusion that garbage collection is without a major cost.
There is a difficuty here, though. Because the program might be modifying the heap while we are marking objects, we have to take extra care to be sure that we don’t improperly flag something as garbage just because all the pointers to it have suddenly been moved into some other data structure that we had already swept.
- In languages like Java where parallel processes/threads are built in to the language capabilities, systems can take the incremental approach event further by running the garbage collector in parallel with the main calculation.
Again, special care has to be taken so that the continuously running garbage collector and the main calculation don’t interfere with one another.
3 Strong and Weak Pointers
Doing Without
OK, garbage collection is great if you can get it.
-
But C++ does not provide it, and C++ compilers don’t really provide the kind of support necessary to implement mark ans sweep or the even more advanced forms of GC.
-
So what can we, as C++ programmers do, when faced with data structures that need to share heap data with one another?
Ownership
One approach that works in many cases is to try to identify which ADTs are the owners of the shared data, and which ones merely use the data.
-
The owner of a collection of shared data has the responsibility for creating it, sharing out pointers to it, and deleting it.
-
Other ADTs that share the data without owning it should never create or delete new instances of that data.
Ownership Example
In this example that we looked at earlier, we saw that if both the Airline object on the left and the Airport objects on the right deleted their own pointers when destroyed, our program would crash.
Ownership Example
We could improve this situation by deciding that the Airline owns the Airport descriptors that it uses. So the Airline object would delete the pointers it has, but the Airports would never do so.
class Airport
{
⋮
private:
vector<Airport*> hasFlightsTo;
};
Airport::~Airport()
{
/* for (int i = 0; i < hasFlightsTo.size(); ++i)
delete hasFlightsTo[i]; */
}
class AirLine {
⋮
string name;
map<string, Airport*> hubs;
};
AirLine::~Airline()
{
for (map<string, Airport*>::iterator i = hubs.begin;
i != hubs.end(); ++i)
delete i->second;
}
Ownership Example
Thus, when the airline object on the left is destroyed, it will delete the Boston, N.Y., and Wash DC objects.
-
Each of those will be deleted exactly once, so our program should no longer crash.
-
This solution isn’t perfect. The Norfolk and Raleigh objects are never reclaimed, so we do wind up leaking memory.
The problem is that, having decided that the Airline owns the Airport descriptors, we have some Airport objects with no owner at all.
Asserting Ownership
I would probably resolve this by modifying the Airline class to keep better track of its Airports.
class AirLine {
⋮
string name;
set<string> hubs;
map<string, Airport*> airportsServed;
};
AirLine::~Airline()
{
for (map<string, Airport*>::iterator i = airportsServed.begin;
i != airportsServed.end(); ++i)
delete i->second;
}
Asserting Ownership (cont.)

The new map tracks all of the airports served by this airline, and we use a separate data structure to indicate which of those airports are hubs.
Now, when an airline object is destroyed, all of its airport descriptors will be reclaimed as well.
Ownership Can Be Too Strong
Ownership is sometimes a bit too strong a relation to be useful.
-
In this example, if we simply say that the list header owns the nodes it points to, then we would delete the first and last node and would leave Baker on the heap.
-
And if we say that the nodes owned the other nodes that they point to and that the list header owns the ones it points to, we would delete the last node twice.
Strong and Weak Pointers
We can generalize the notion of ownership by characterizing the various pointer data members as strong or weak.
-
A strong pointer is a pointer data member that indicates that the object pointed to must remain in memory.
-
A weak pointer is a pointer data member that is allowed to point to data that might have been deleted.
- (Obviously, we never want to follow a weak pointer unless we are sure that the data has not, in fact, been deleted.)
When an object containing pointer data members is destroyed, it deletes its strong pointer members and leaves its weak ones alone.
Strong and Weak SLL
In this example, if we characterize the pointers as shown:
struct SLNode {
string data;
SLNode* next; // strong
⋮
~SLNode () {delete next;}
};
class List {
SLNode* first; // strong
SLNode* last; // weak
public:
⋮
~List()
{
delete first; // OK, because this is strong
/*delete last;*/ // Don't delete. last is weak.
}
};
then our program will run correctly.
Picking the Strong Ones
The key idea is to select the smallest set of pointer data members that would connect together all of the allocated objects, while giving you exactly one path to each such object.
Strong and Weak DLL
Similarly, in a doubly linked list, we can designate the pointers as follows:
struct DLNode {
string data;
DLNode* prev; // weak
DLNode* next; // strong
⋮
~DLNode () {delete next;}
};
class List {
DLNode* first; // strong
DLNode* last; // weak
public:
⋮
~List() {delete first;}
};
and so achieve a program that recovers all garbage without deleting anything twice.
3.1 Smart Pointers can be Strong or Weak
C++ smart pointers actually come in two “flavors”
shared_ptrgives us strong pointers that are reference countedweak_ptrgives us weak pointers that do not affect reference counts, but can be assigned to and from strong pointers.
For example, if we were doing a doubly linked list, this would not be useful:
struct DLNode {
string data;
shared_ptr<DLNode> prev;
shared_ptr<DLNode> next;
⋮
~DLNode () {delete next;}
};
class List {
shared_ptr<DLNode> first;
shared_ptr<DLNode> last;
public:
⋮
};
because the cycles induced by the prev and next pointers would prevent any nodes’ reference counts from dropping to zero.
But if we make the back pointer weak:
struct DLNode {
string data;
weak_ptr<DLNode> prev;
shared_ptr<DLNode> next;
⋮
~DLNode () {delete next;}
};
class List {
shared_ptr<DLNode> first;
shared_ptr<DLNode> last;
public:
⋮
};
then the list should have no cycles, and reference counting should work just fine.
4 Java Programmers Have it Easy
Java has included automatic garbage collection since its beginning.
-
From a practical point of view, sharing in Java is actually easier (and more common) than deep copying.
-
Java programmers typically are unconcerned with many of the memory management errors that C++ programmers must strive to avoid.
C++ programmers may sometimes sneer at the slowdown caused by garbage collection. The collector implementations, however, continue to evolve. In fact, current versions of Java commonly offer multiple garbage collectors, one which can be selected at run-time in an attempt to find one whose run-time characteristics (i.e., how aggressively it tries to collect garbage and how much of the time it can block the main program threads while it is working) that matches your program’s needs.
Java programmers sometimes face an issue of running out of memory because they have inadvertently kept pointers to data that they no longer need. This is a particular problem in implementing algorithms that use caches or memoization to keep the answers to prior computations in case the same result is needed again in the future. Because of this, Java added a concept of a weak reference (pointer) that can be ignored when checking to see if an object is garbage and that gets set to null if the object it points to gets collected.
1: Though, somewhat confusingly, they call them “references” instead of “pointers”. But they really are more like C++ pointers than like C++ references because you
-
obtain one of these pointer/references by allocating an object on the heap via the operator new,
-
can assign the value “null” to one of these to indicate that it isn’t pointing at anything at all, and
-
can assign a new address to one of these to make it point at some different object on the heap
All three of these properties are true of C++ pointers but not of C++ references. So Java “references” really are the equivalent of C++ “pointers”.
By renaming them, Java advocates are able to boast that Java is a simpler language because it doesn’t have pointers. That’s more than a little disingenuous, IMO. (If it looks like a duck, swims like a duck, and quacks like a duck,…)
In actual fact, Java programs are absolutely swimming in pointers, but they pointers just aren’t as problematic as they are in C++.